![]()
本文作者: slience_me
注意力、自注意力和多头注意力的区别
理解注意力(Attention)、自注意力(Self-Attention)和多头注意力(Multi-Head Attention)之间的区别非常重要,因为它们是自然语言处理(NLP)和深度学习模型中关键的组件。
注意力(Attention)
- 注意力机制是一种机制,允许模型集中注意力在输入的不同部分,以便更好地理解或处理数据。在自然语言处理中,注意力机制常用于对输入序列中不同位置的信息进行加权汇总,以便在生成输出时对输入中不同位置的信息进行加权。
- 例如,在机器翻译任务中,如果要将一个句子从一种语言翻译成另一种语言,注意力机制可以帮助模型确定在翻译每个词时应该关注源语言句子的哪些部分。
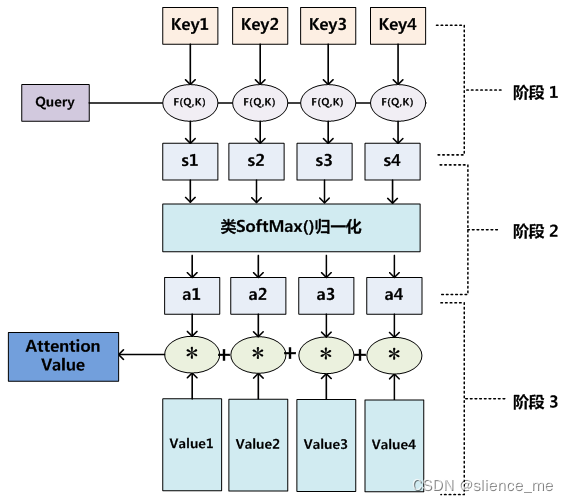
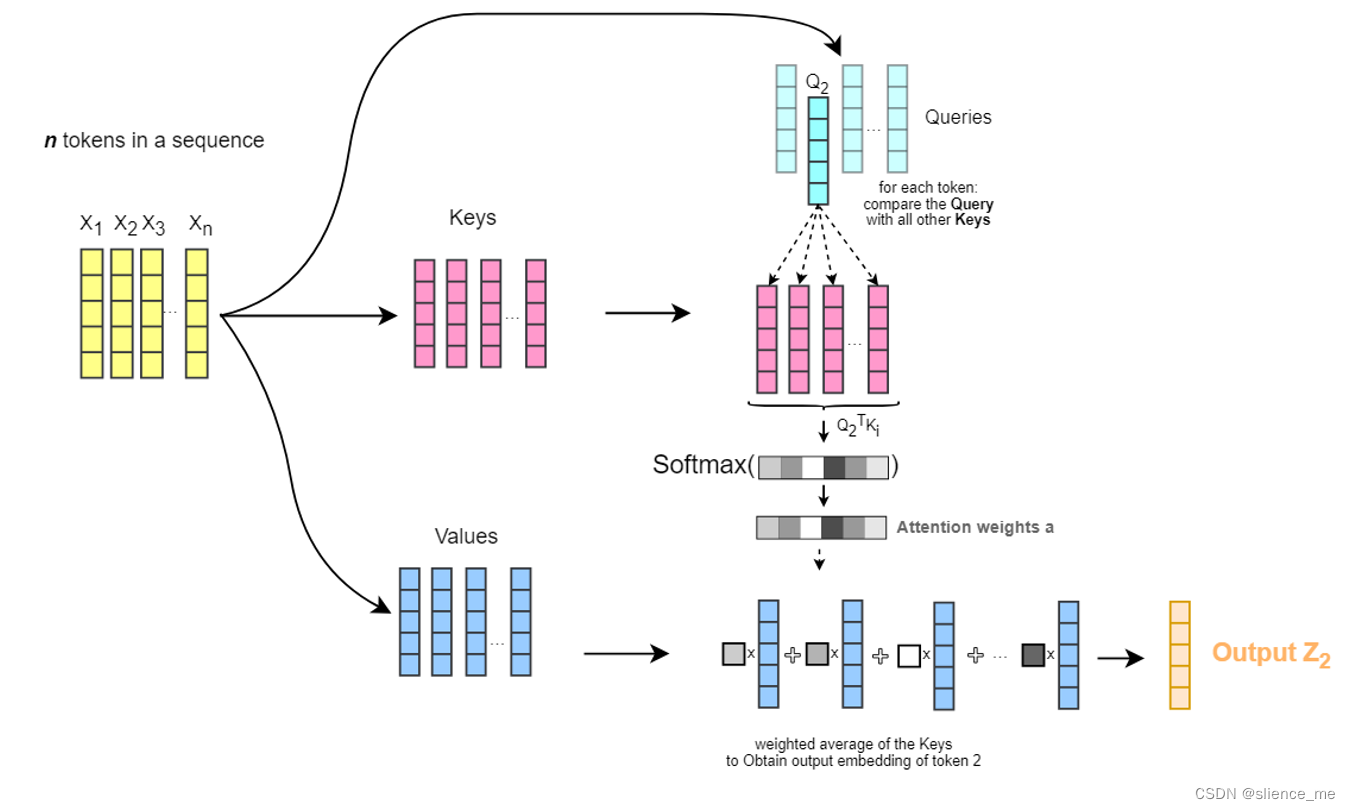

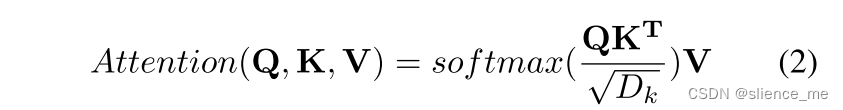

自注意力(Self-Attention)
- 自注意力是一种特殊类型的注意力机制,其中输入序列中的每个元素都用于计算其自己与其他元素之间的关系。简而言之,它允许模型在输入序列中的不同位置之间进行交互,以捕获序列内部的依赖关系。
- 举例来说,在自然语言处理中,对于一个句子,自注意力机制可以帮助模型理解每个词与句子中其他词之间的关系,从而更好地表示句子的语义信息。
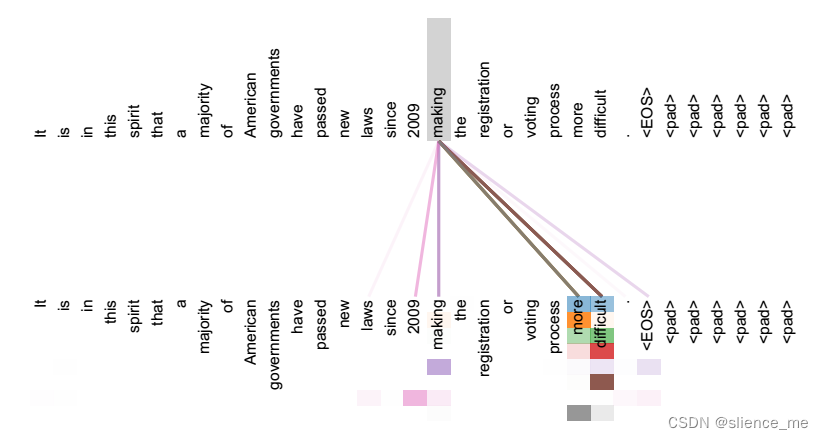
Self Attention 机制,顾名思义,指的是 Source 内部元素之间或者 Target 内部元素之间发生的 Attention 机制,也可以理解为 Source = Target 这种特殊情况下的 Attention 机制,具体计算过程和 Soft Attention 是一样的。
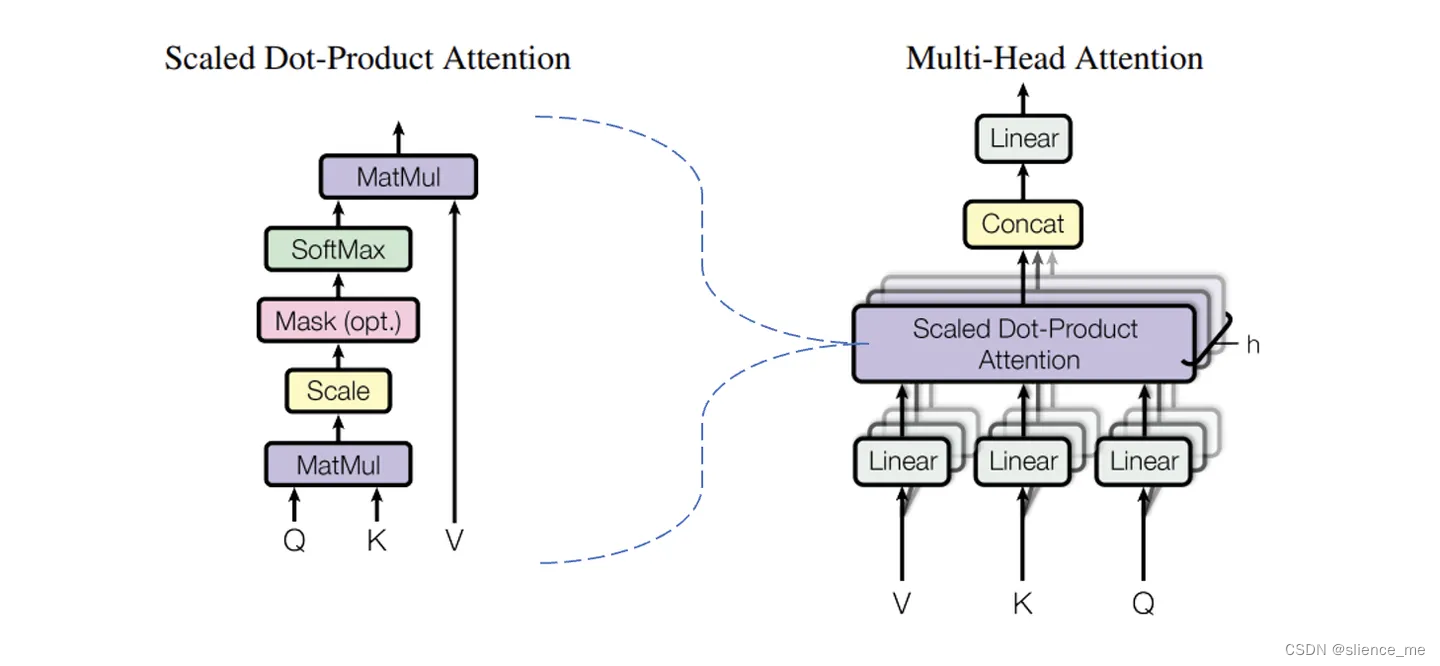
多头注意力(Multi-Head Attention)
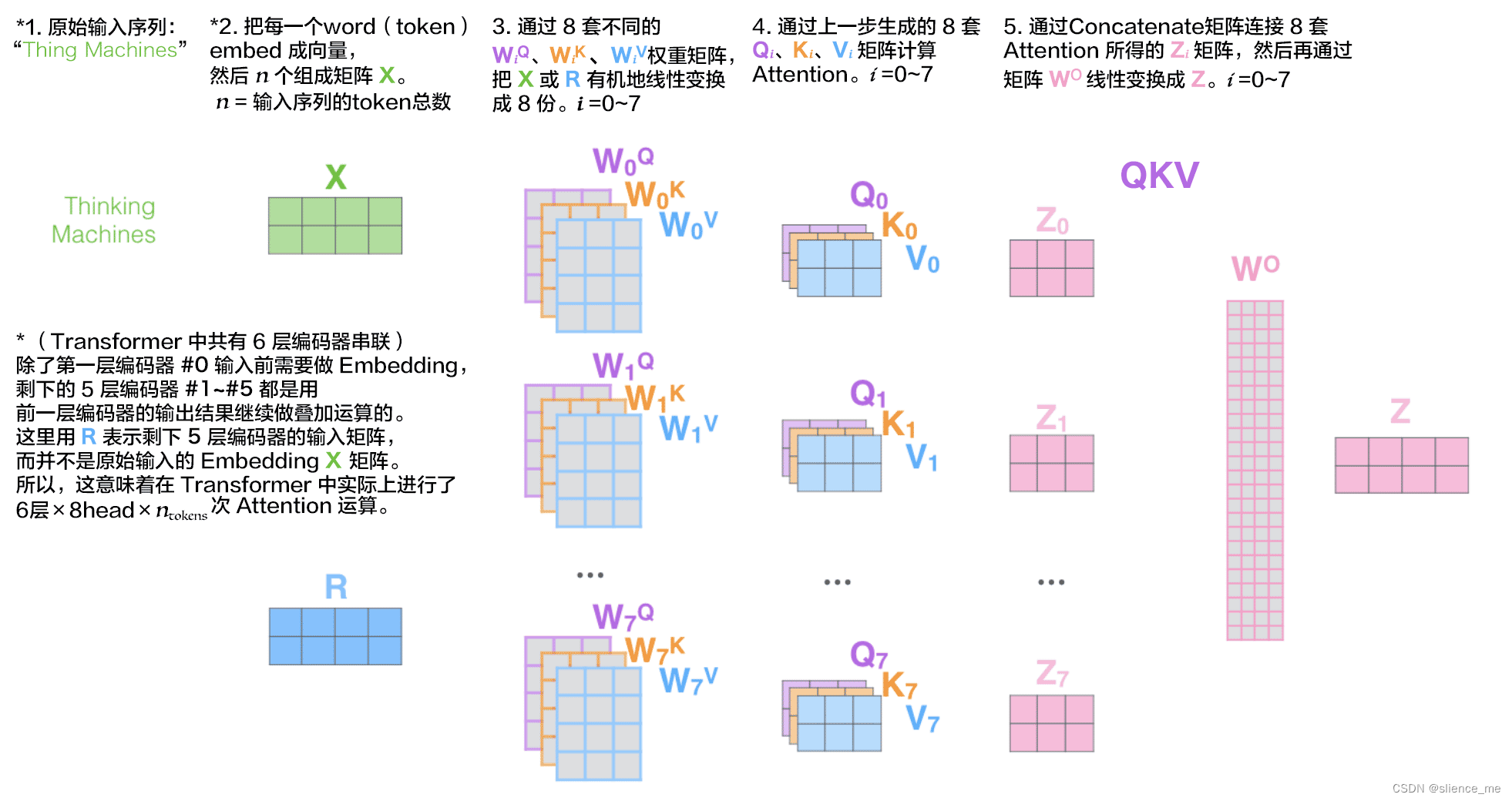
- 多头注意力是一种注意力机制的扩展形式,在其中,模型使用多个注意力头(即并行的注意力子机制)来捕获不同的关注点。每个注意力头都会学习不同的注意力权重,然后将它们组合起来以获得更全面的表示。
- 例如,在Transformer模型中,每个注意力头可以关注输入序列中的不同方面,比如语义信息、句法信息等。通过使用多个注意力头,模型能够从多个角度更全面地理解输入序列。
总之,自注意力是一种特殊类型的注意力机制,用于在输入序列内部建立元素之间的关系;而多头注意力是一种扩展形式,使用多个并行的自注意力头来捕获不同的关注点,以更全面地理解输入序列。
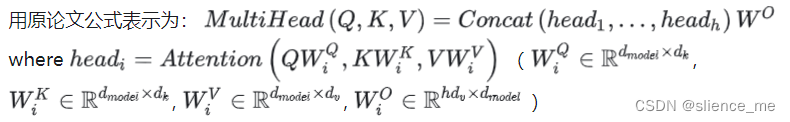
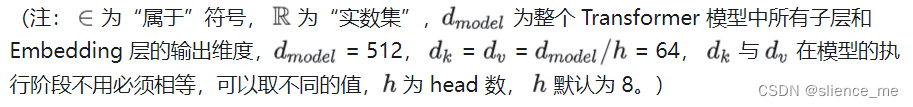
参考内容: