注意力机制
- 注意力机制(Attention Mechanism)是一种在深度学习模型中用于加强不同输入元素之间关联性的方法。它模拟了人类感知中的注意力过程,允许模型在处理数据时选择性地关注重要的信息,以提高性能。 以下是有关注意力机制在模型设计中的重要性和应用:
自然语言处理(NLP):
- 在自然语言处理中,注意力机制常用于机器翻译、文本摘要、问答等任务。通过注意力机制,模型可以在生成输出时关注输入序列中与当前生成标记相关的部分。
- 注意力机制有助于提高翻译质量,生成更准确的摘要,以及在问答任务中定位正确的上下文信息。
计算机视觉:
- 在计算机视觉中,注意力机制可以用于目标检测、图像分类和图像分割。通过注意力机制,模型可以在处理图像时关注与任务相关的图像区域或特征。
- 这有助于改善目标检测的准确性,特别是在多目标场景中,以及提高图像分类性能。
强化学习:
- 在强化学习中,注意力机制可以用于选择执行动作的策略。模型可以在每个时间步上选择性地关注不同状态或观察,以优化决策。
- 注意力机制在增强学习中的应用可以提高智能体的性能,特别是在复杂环境中的任务。
自动编码器和生成对抗网络:
- 注意力机制还可以用于自动编码器(Autoencoders)和生成对抗网络(GANs)等模型,以改善特征提取和生成过程。
- 通过引入注意力机制,模型可以更好地选择和生成重要的特征或样本。
跨模态任务:
- 在处理跨模态数据(例如,文本和图像的关联)时,注意力机制可以帮助模型在不同模态之间建立关联,以实现更精确的任务。
- 总之,注意力机制是深度学习模型设计中的一个重要组成部分,可以提高模型的性能、可解释性和适应性。通过引入注意力机制,模型可以更有效地处理大量信息,选择性地关注重要信息,并在各种任务中获得更好的结果。因此,注意力机制已成为各种深度学习任务中的不可或缺的工具。
1. 注意力机制及其应用
1.1 注意力机制的定义
- <font color=#E91E63>Attention,对图像中不同区域或者句子中的不同部分给予不同的权重,从而找到感兴趣的区域,抑制不感兴趣区域</font>
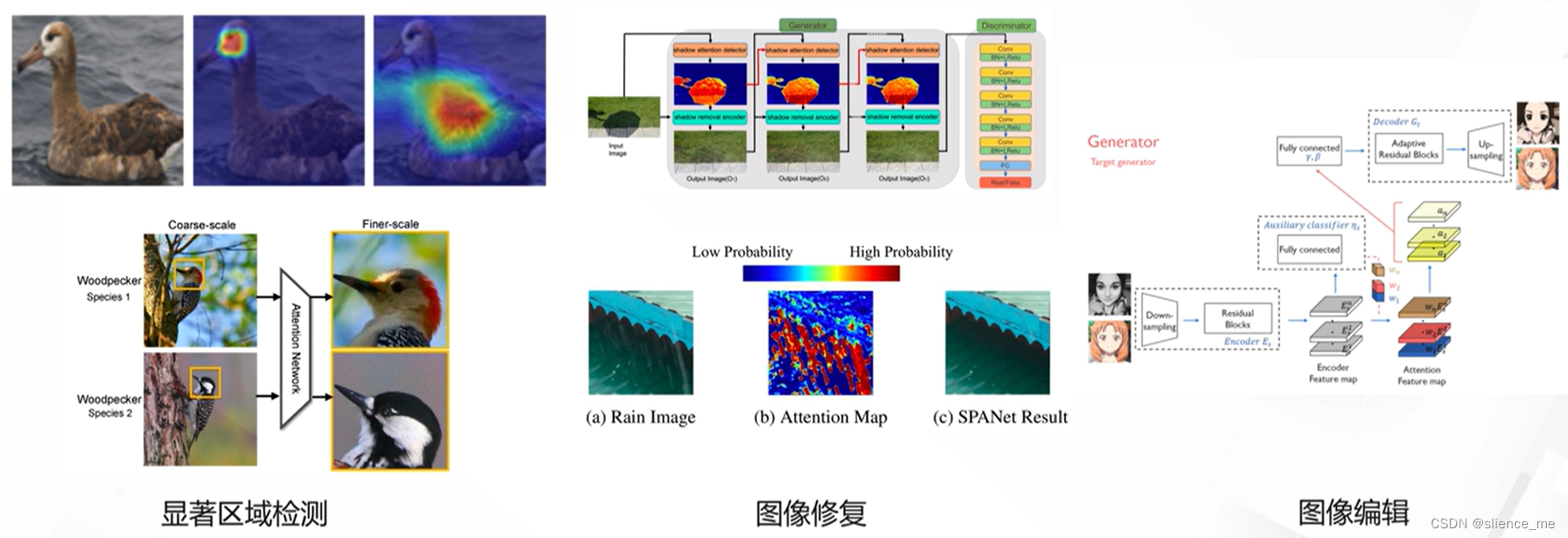
1.2 注意力机制的典型应用
- <font color=#E91E63>显著目标检测,图像修复,图像编辑</font>
- <font color=#E91E63>机器翻译,摘要生成,图像描述</font>
2. 注意力模型设计
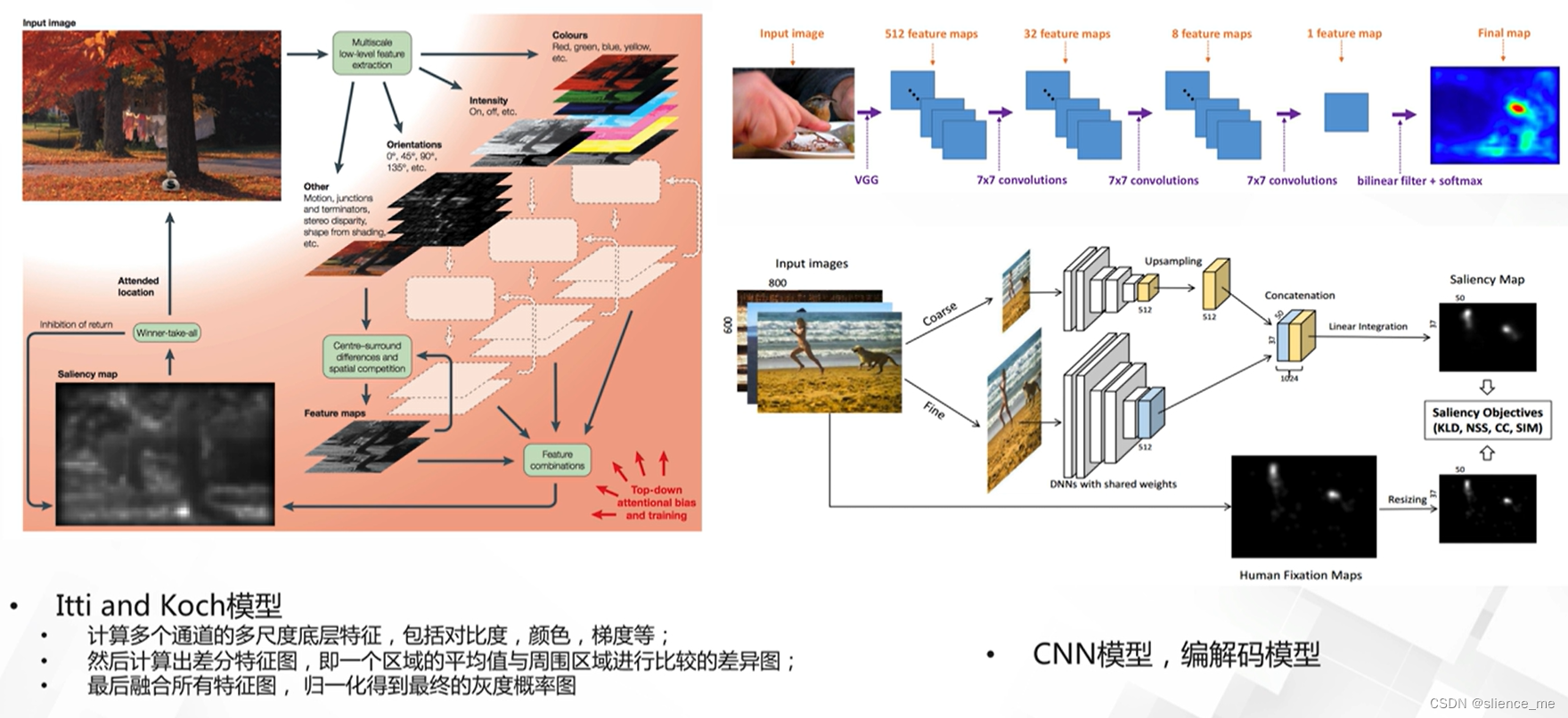
2.1 空间注意力机制
- <font color=#E91E63>显著目标检测模型,Saliency Object Detection,预测显著目标概率图</font>
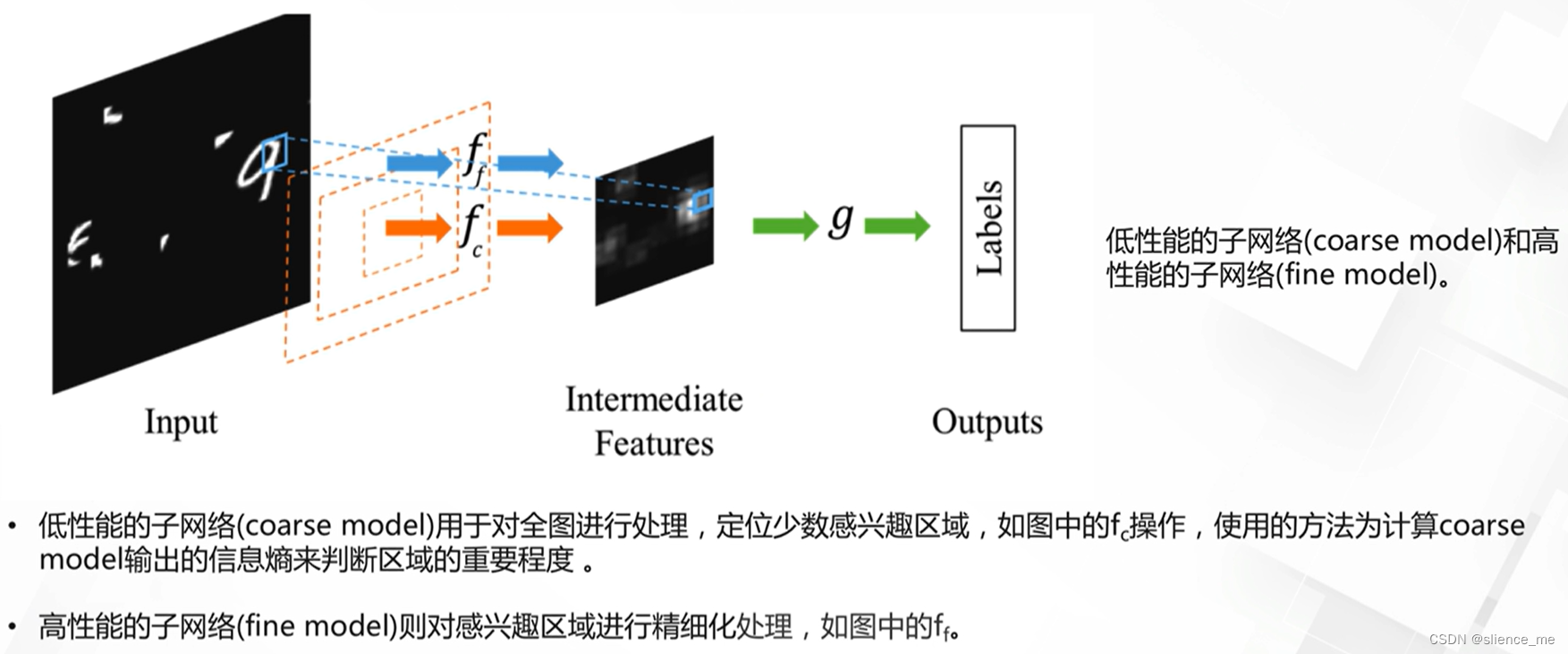
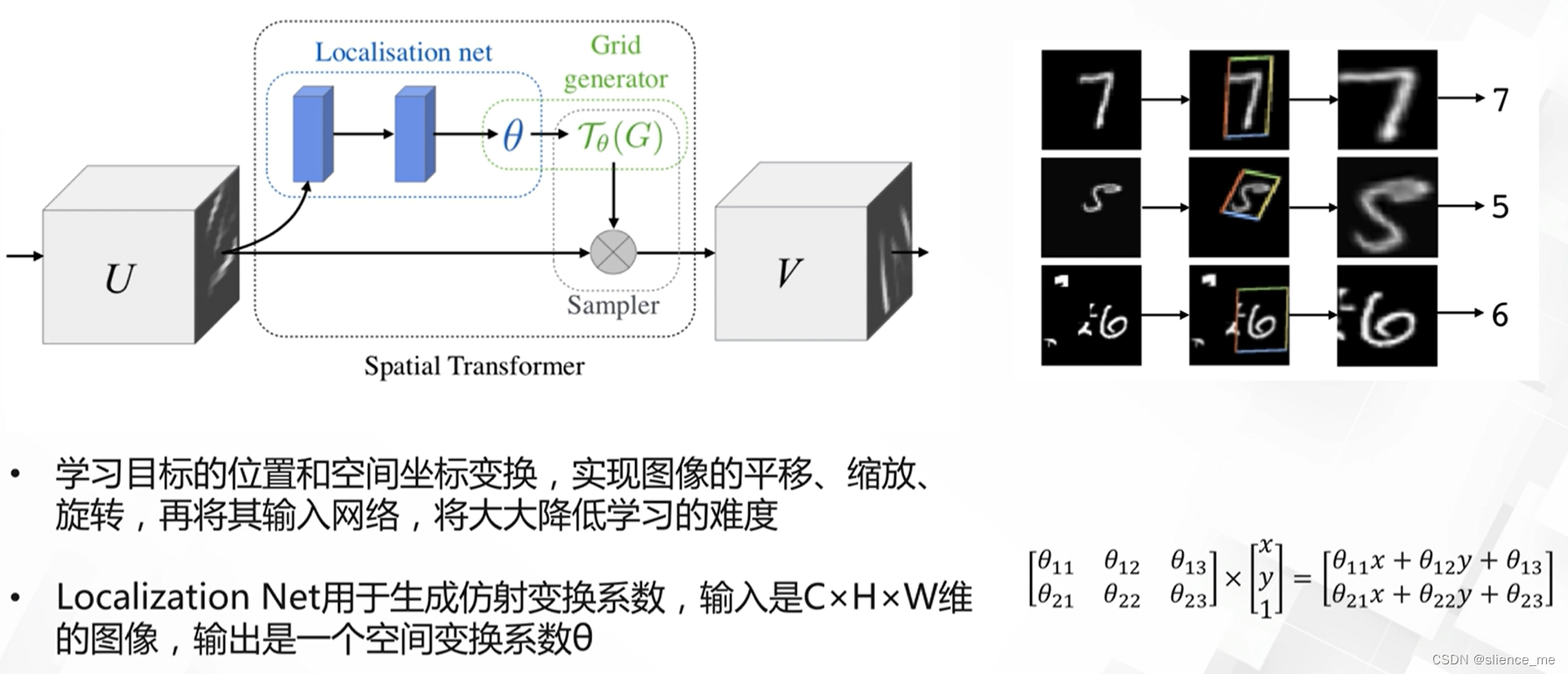
2.2 空间注意力模型
- <font color=#E91E63>动态容量网络,Dynamic Capacity Networks</font>
- <font color=#E91E63>空间变换网络,STN(spatial transform network)</font>
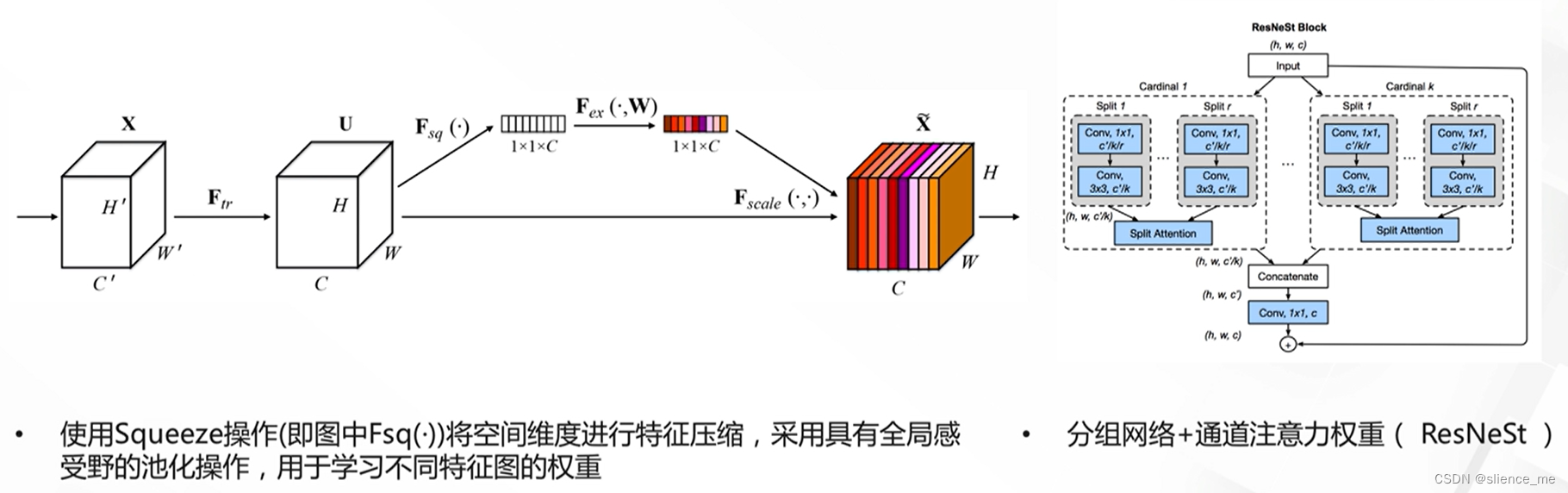
2.3 通道注意力机制
- <font color=#E91E63>SENet ,2017年ImageNet分类冠军网络</font>
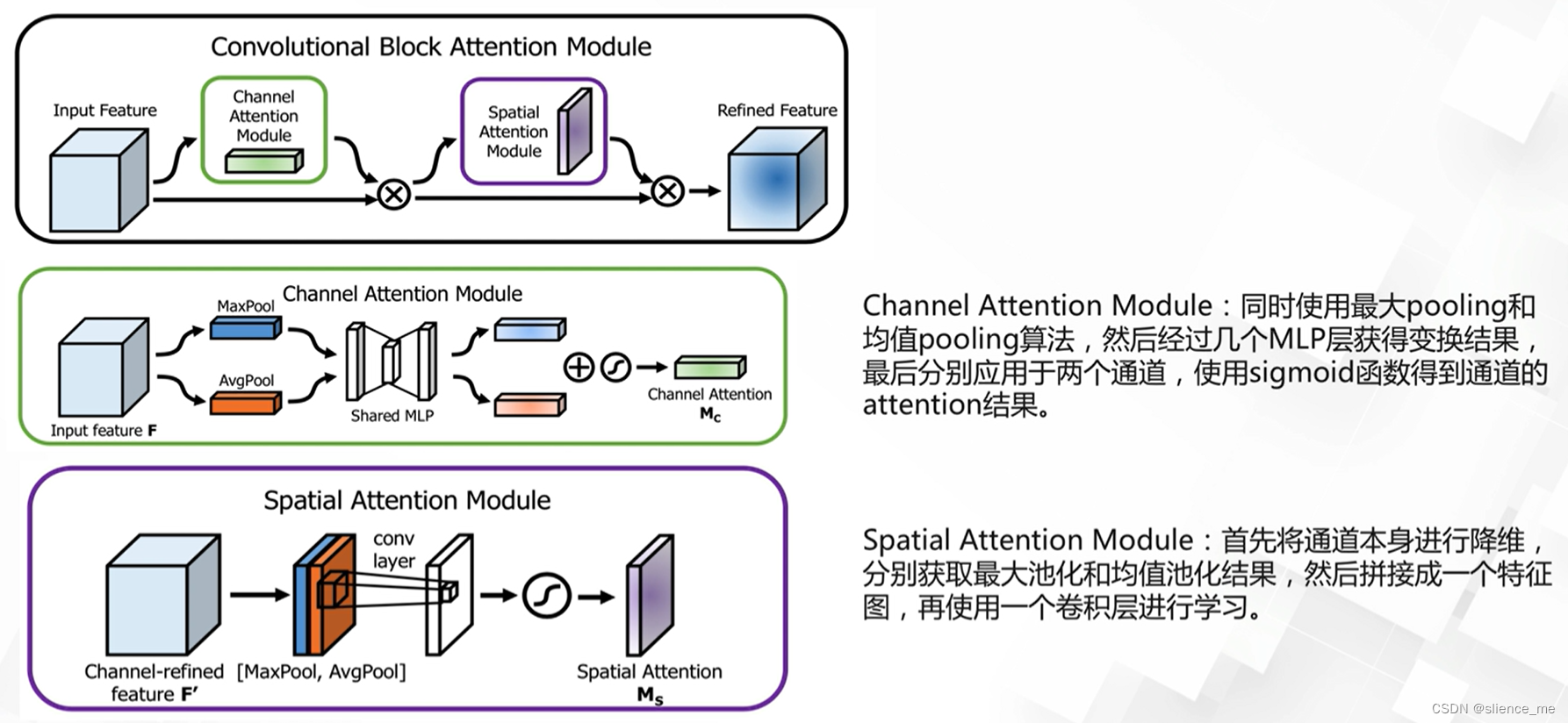
2.4 空间与通道注意力机制
- <font color=#E91E63>CBAM,Convolutional Block Attention Module,同时从空间维度和通道维度进行Attention</font>
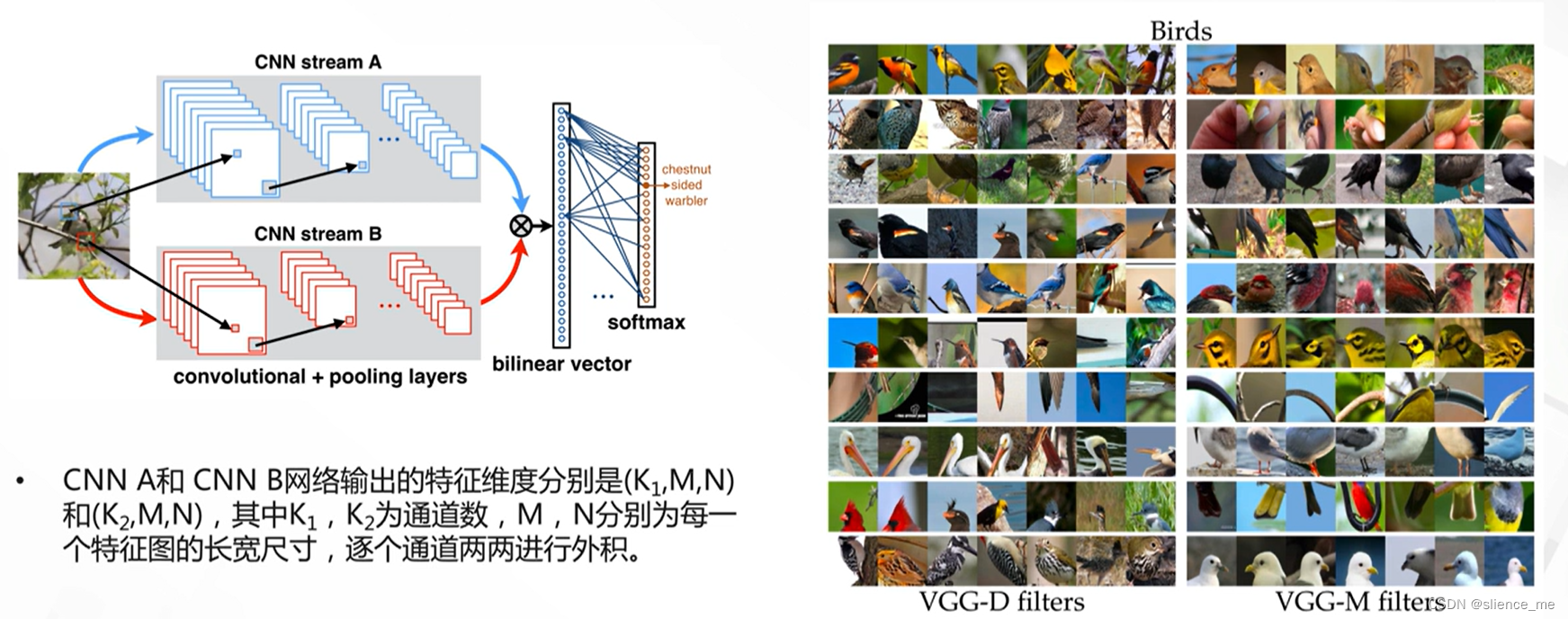
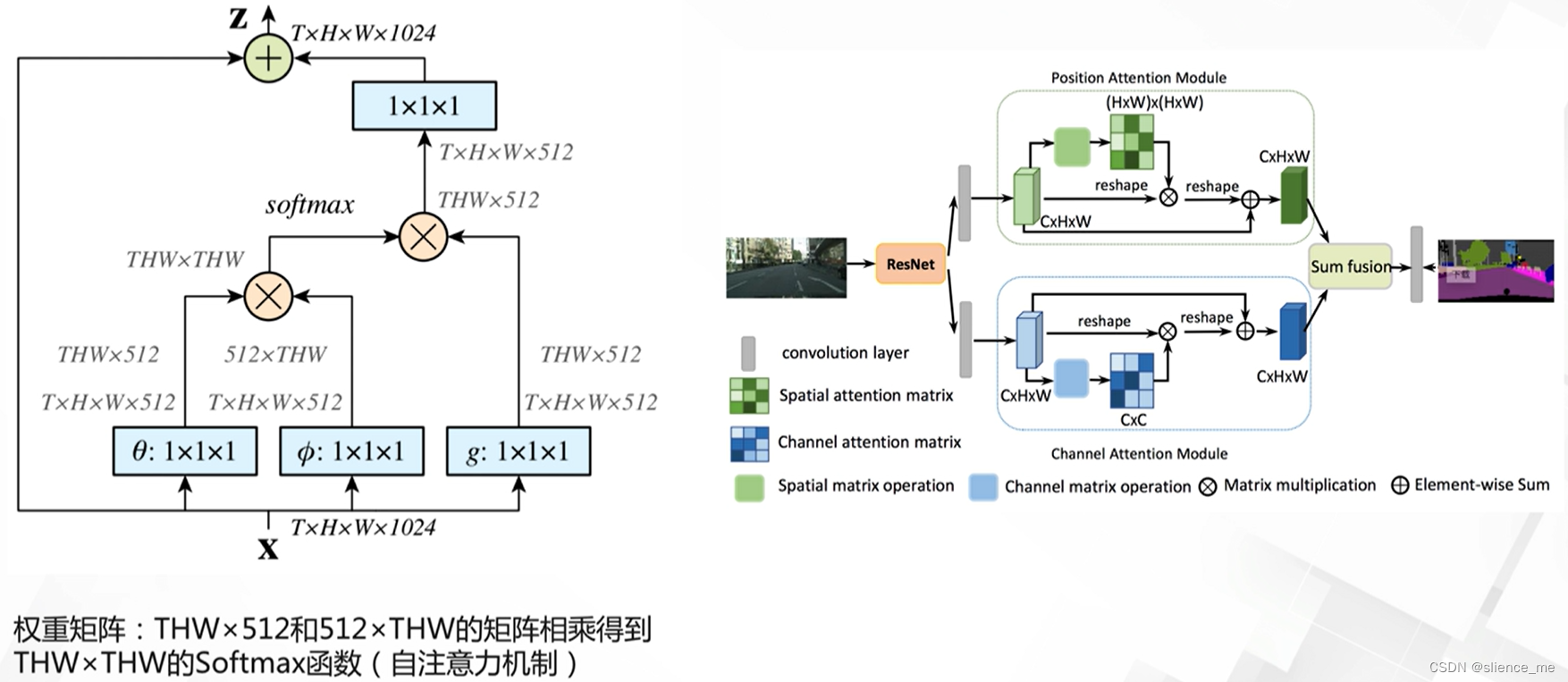
2.5 自注意力机制
- <font color=#E91E63>双线性模型,使用特征外积操作获得自注意力矩阵</font>
- <font color=#E91E63>非局部卷积,Non-local Network</font>
2.5 级联attention
- <font color=#E91E63>Residual Attention Network(2018)</font>


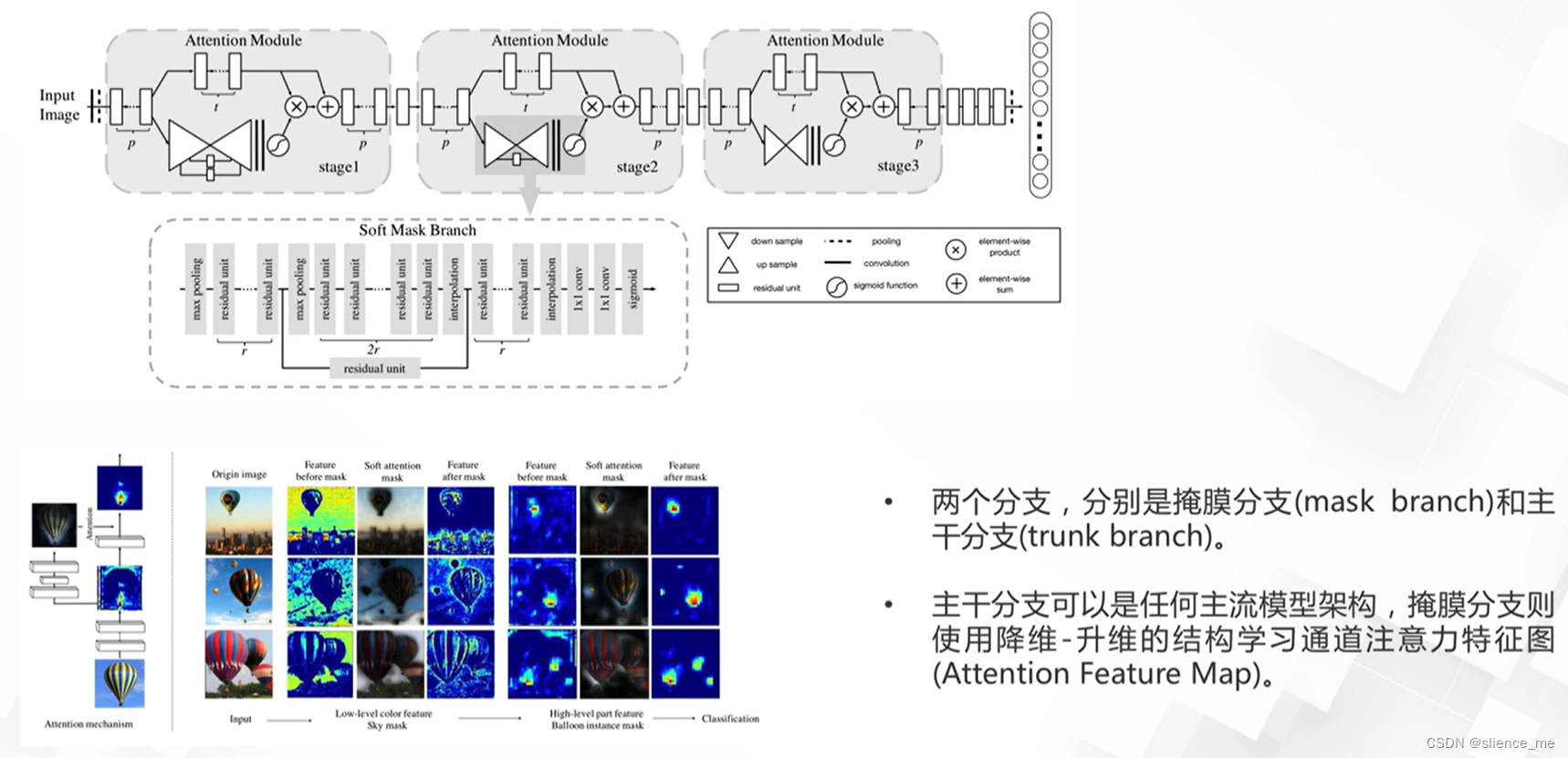
动态网络
- 动态网络(Dynamic Network)是一种神经网络架构,与传统的静态神经网络不同,它允许在模型训练和推理期间根据输入数据的特性动态调整网络结构。这种灵活性可以帮助网络更好地适应不同数据分布和任务需求。以下是一些关于动态网络的设计和应用方面的考虑:
自适应结构:
- 在动态网络中,网络结构可以根据输入数据的特性自动调整。这意味着网络可以动态地添加或删除层、模块或通道,以适应不同的输入数据。
- 自适应结构可以提高模型的泛化性能,使其更适合于变化的数据分布,特别是在面对不平衡数据或噪声数据时。
注意机制:
- 动态网络通常使用注意力机制(Attention Mechanism),以根据输入数据的不同部分调整网络的关注度。这有助于模型更好地关注重要的信息。
- 注意机制在自然语言处理(NLP)和计算机视觉中的动态网络中得到广泛应用,例如,自然语言问答和图像标注任务。
遗忘机制:
- 一些动态网络可以学习遗忘不需要的信息,从而提高模型的效率。这在处理长序列或大型数据时尤其有用。
- 遗忘机制可以降低模型的计算复杂度,同时保持高性能。
模块化设计:
- 动态网络通常采用模块化的设计,模块可以根据需要堆叠或重复。这种设计使得网络更易于扩展和调整。
- 模块化设计对于构建可重复使用的模型部分和快速迭代设计是有利的。
预测网络结构:
- 有些动态网络可以预测网络的结构,以更好地适应特定任务。这通常涉及到使用强化学习等方法来优化网络的结构。
- 预测网络结构的方法对于模型设计的自动化和优化非常有前景。
实时决策:
- 动态网络可以用于实时决策,例如自动驾驶、机器人控制或游戏决策,因为它们能够根据实时输入进行动态调整。
- 总之,动态网络是一种具有适应性和灵活性的神经网络架构,可以根据不同的任务和输入数据自动或手动地调整网络结构。这种灵活性使动态网络适用于各种不同的应用领域,尤其是需要适应变化的数据和任务要求的情况。
1. 动态网络的定义
<font color=#E91E63>网络结构在训练或推理时表现出不同的结构、对不同的样本,表现出不同</font>
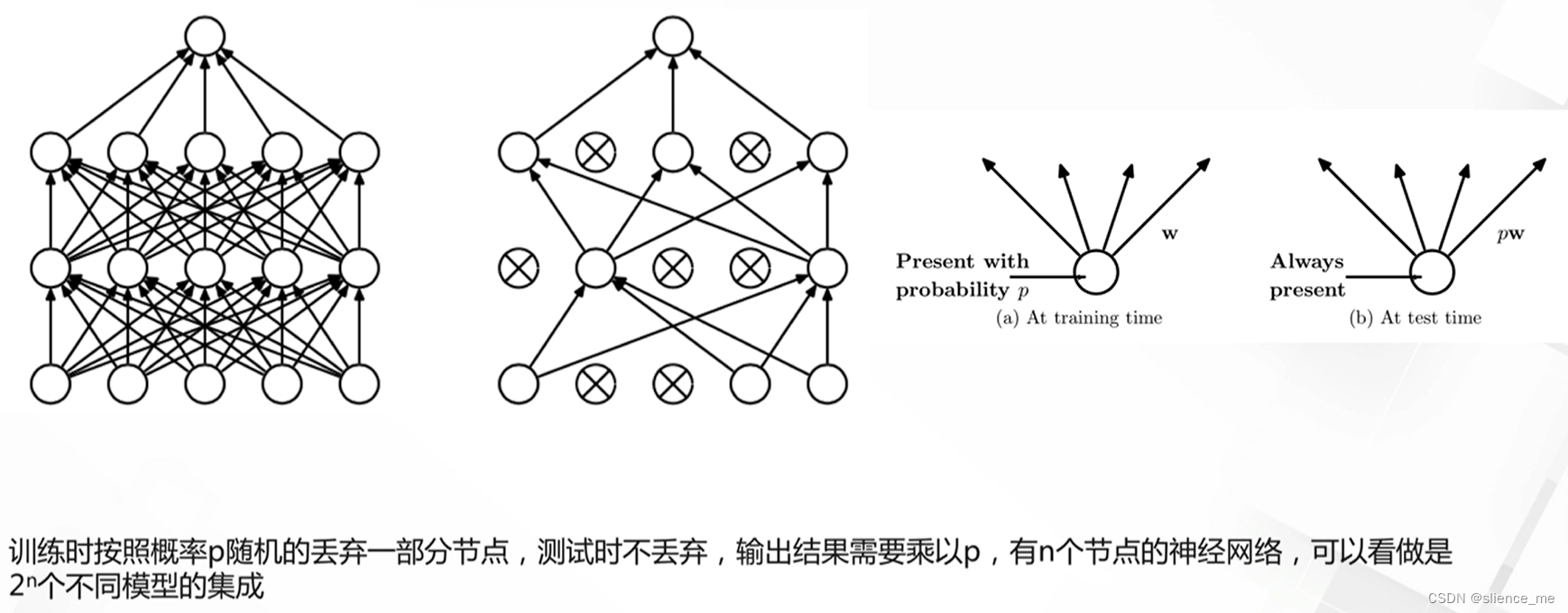
- <font color=#E91E63>研究动态网络原因:提高模型的泛化能力,减少计算量</font>
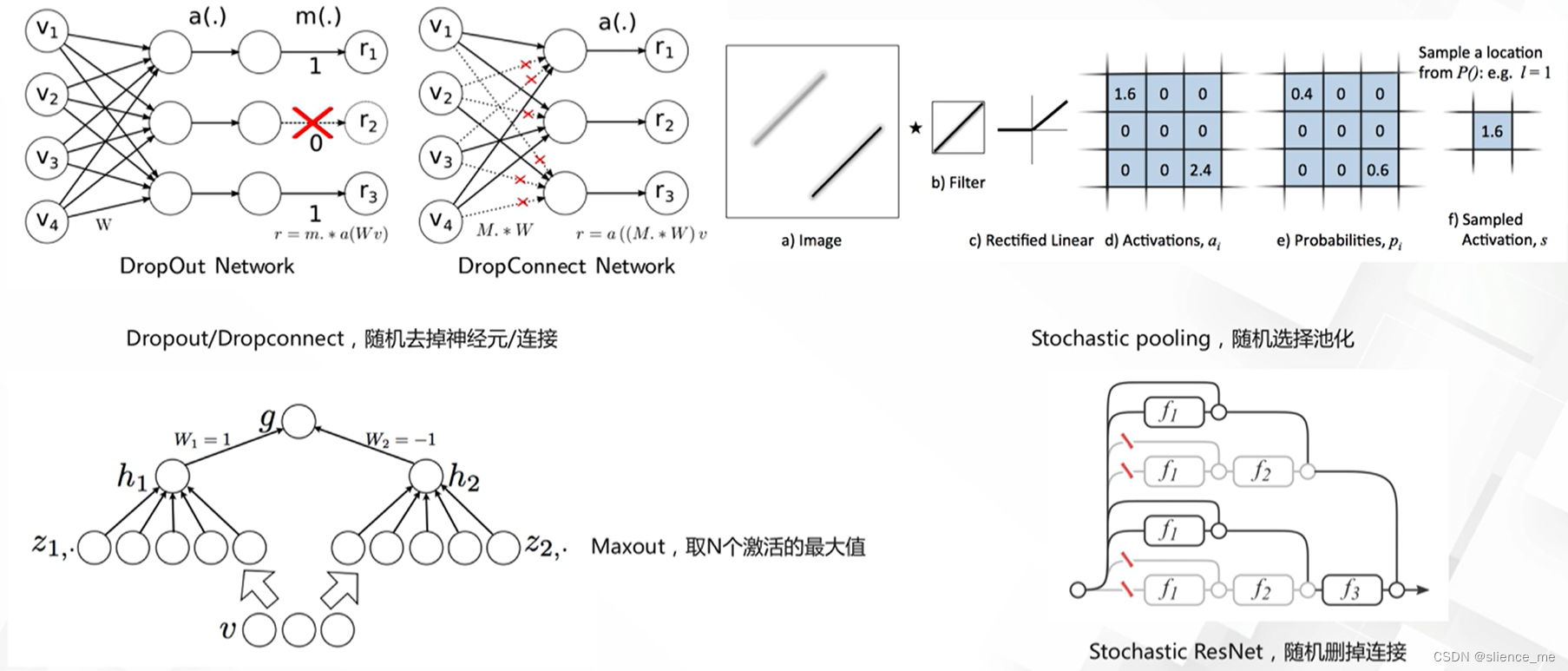
2. 基于丢弃策略的动态网络
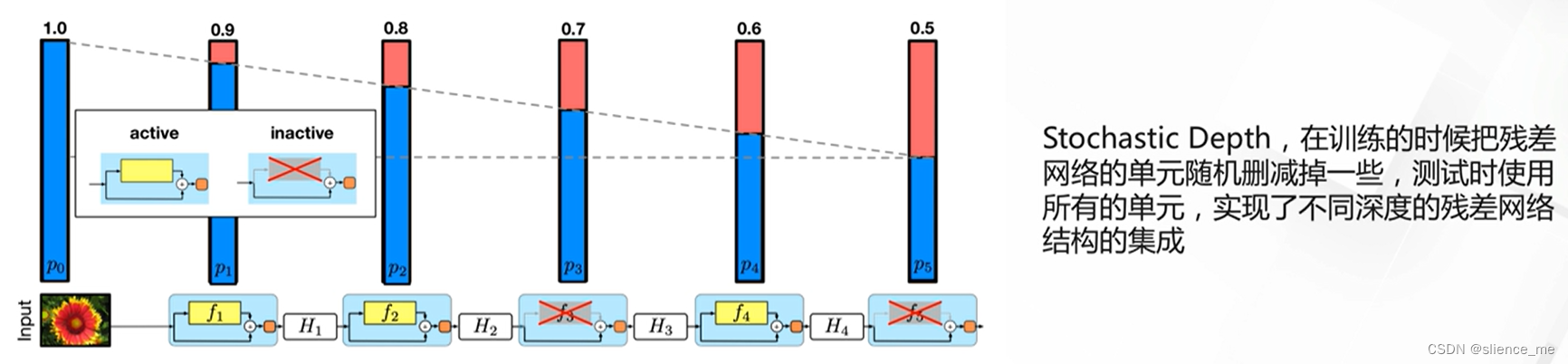
2.1 随机深度残差网络
- <font color=#E91E63>残差网络可以看作是多个不同深度模型的集成,“Residual networks behave like ensembles of relatively shallow networks”</font>
2.2 模块丢弃残差网络
- <font color=#E91E63>Blockdrop,学习丢弃策略的残差模块</font>
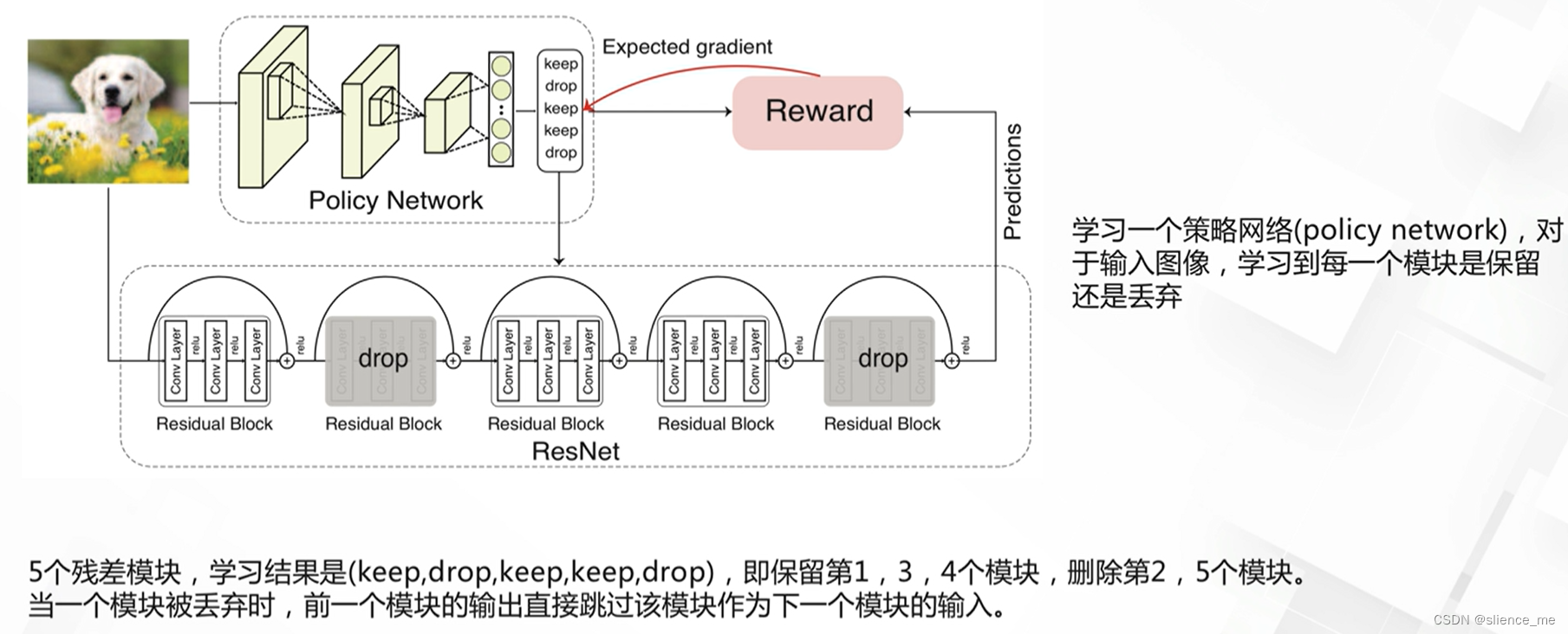
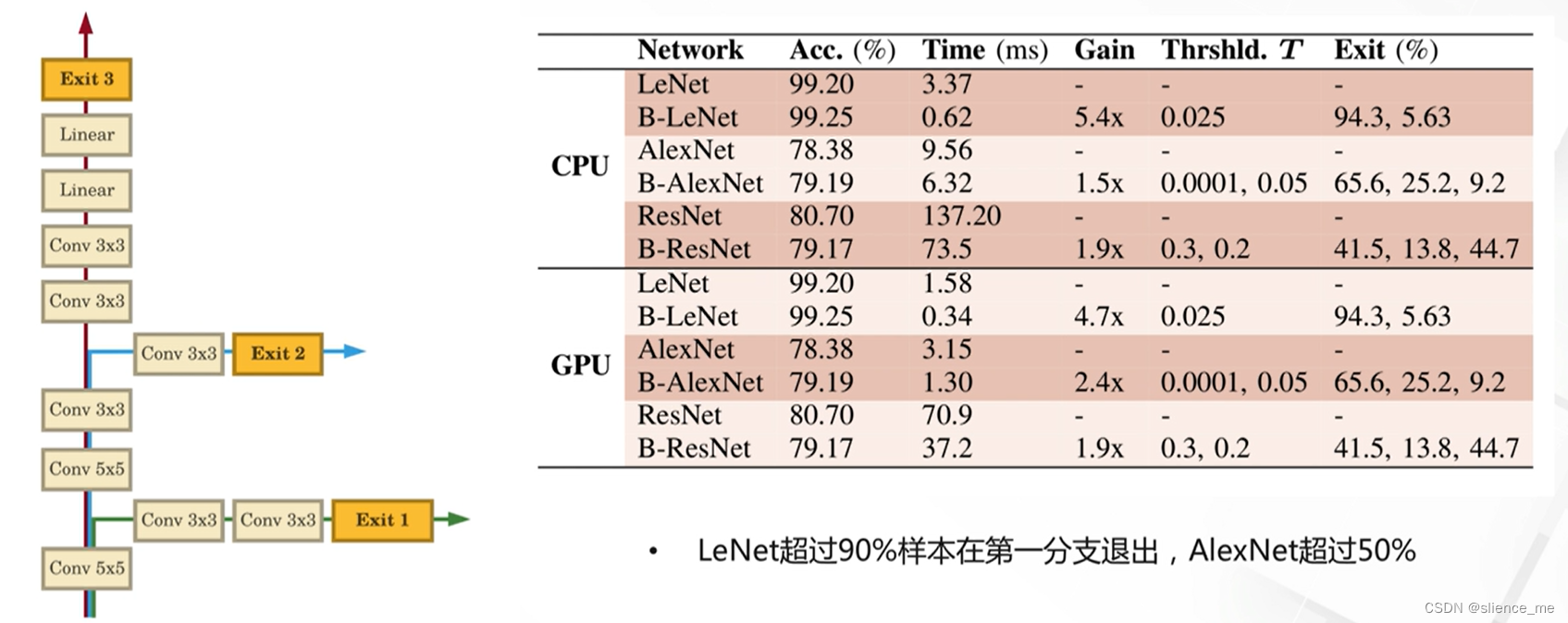
2.3 BranchyNet网络
- <font color=#E91E63>对于不同的样本,根据累积的嫡来决定是否提前退出推理,越简单的样本,计算量越小</font>
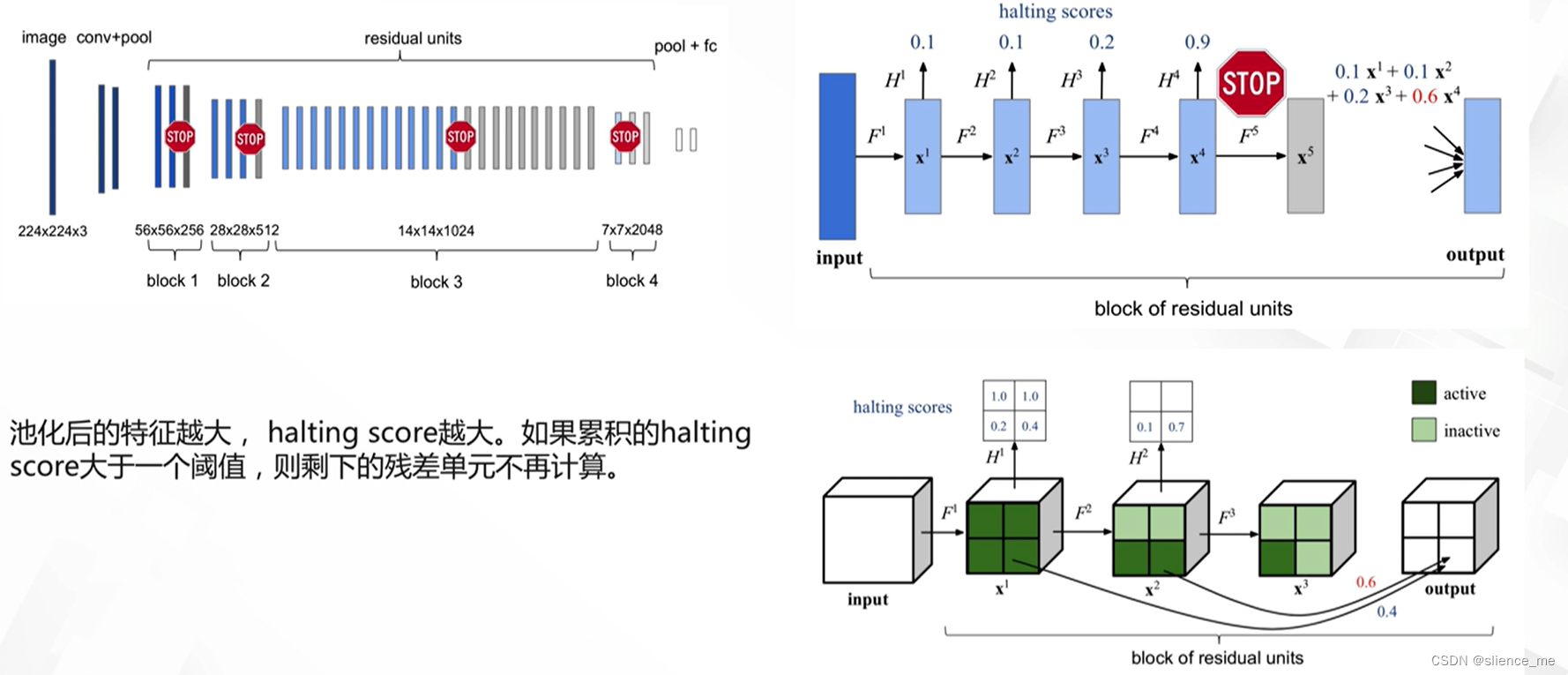
2.4 Spatially Adaptive Computing Time(SACT)
- <font color=#E91E63>对每一个残差单元的输出添加一个分支,用于预测halting score(累积概率,0~1)</font>
3. 基于注意力机制的动态网络
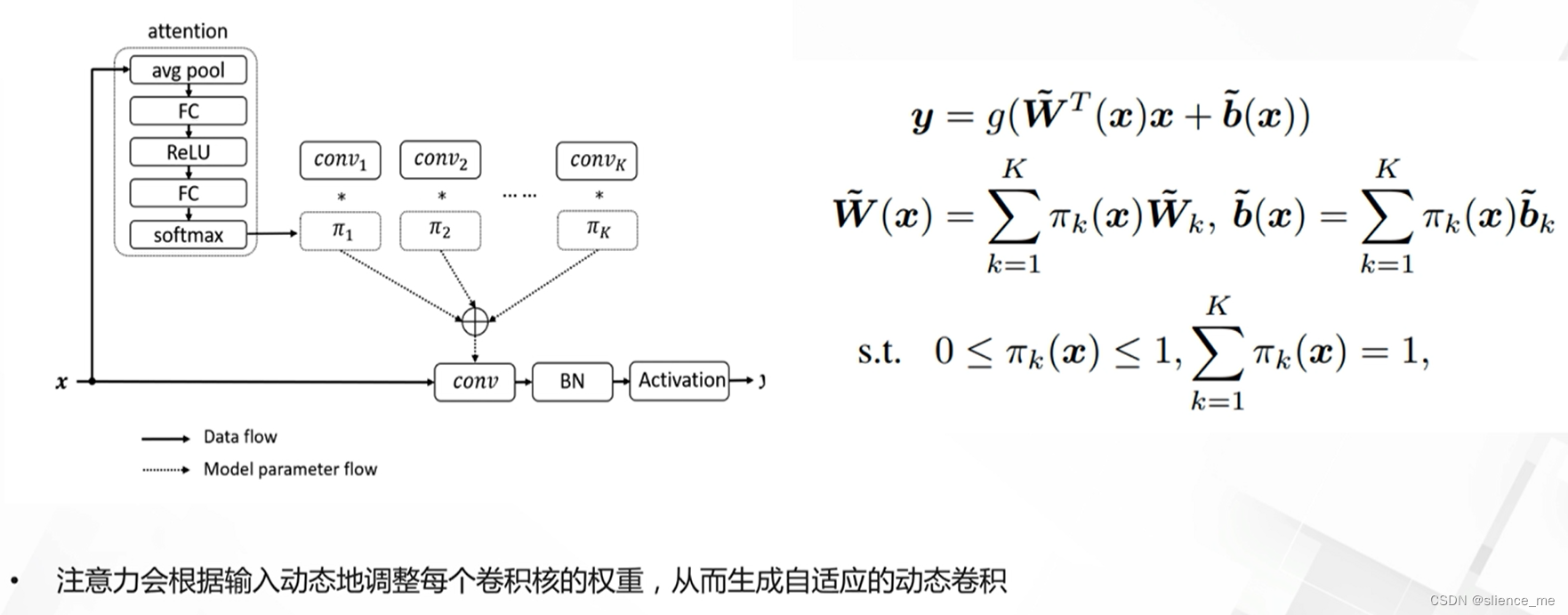
3.1 动态卷积(Dynamic Convolution)
- <font color=#E91E63>根据输入图像,采用注意力机制自适应地调整卷积参数</font>
3.2 动态空间模型(Dynamic RegionAware Convolution)
- <font color=#E91E63>根据输入图像不同特征图上不同区域,采用不同的卷积核进行计算</font>
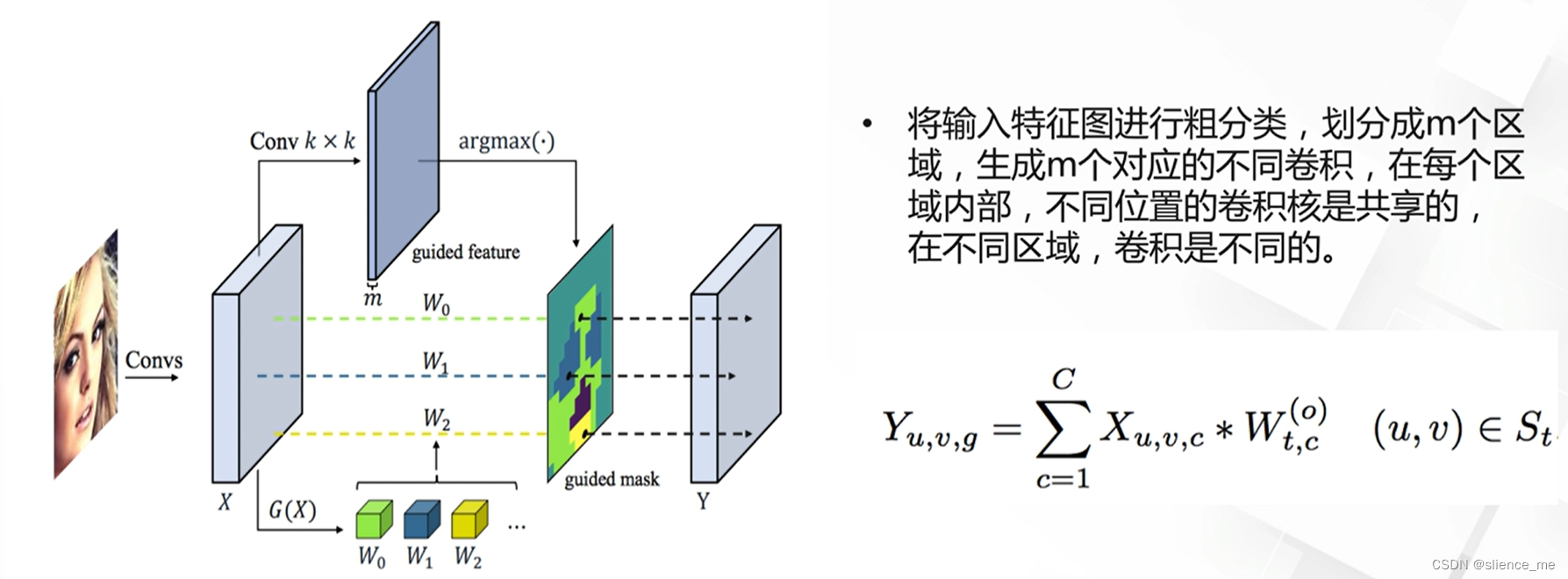
4. 基于合并策略的动态网络
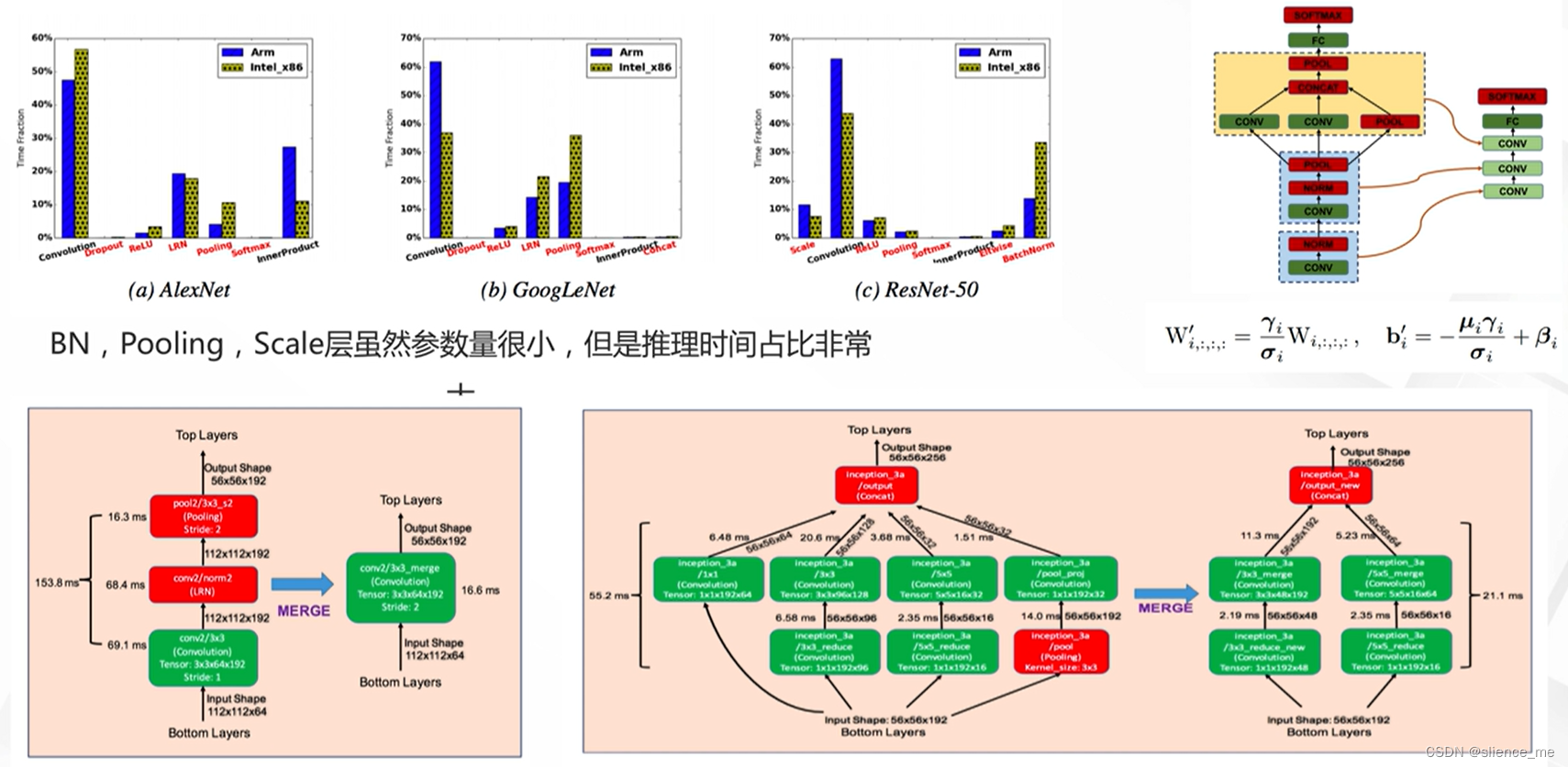
4.1 Deep Rebirth
- <font color=#E91E63>合并非tensor层,包括BN层,Pooling , Scale层,以及多个分支</font>
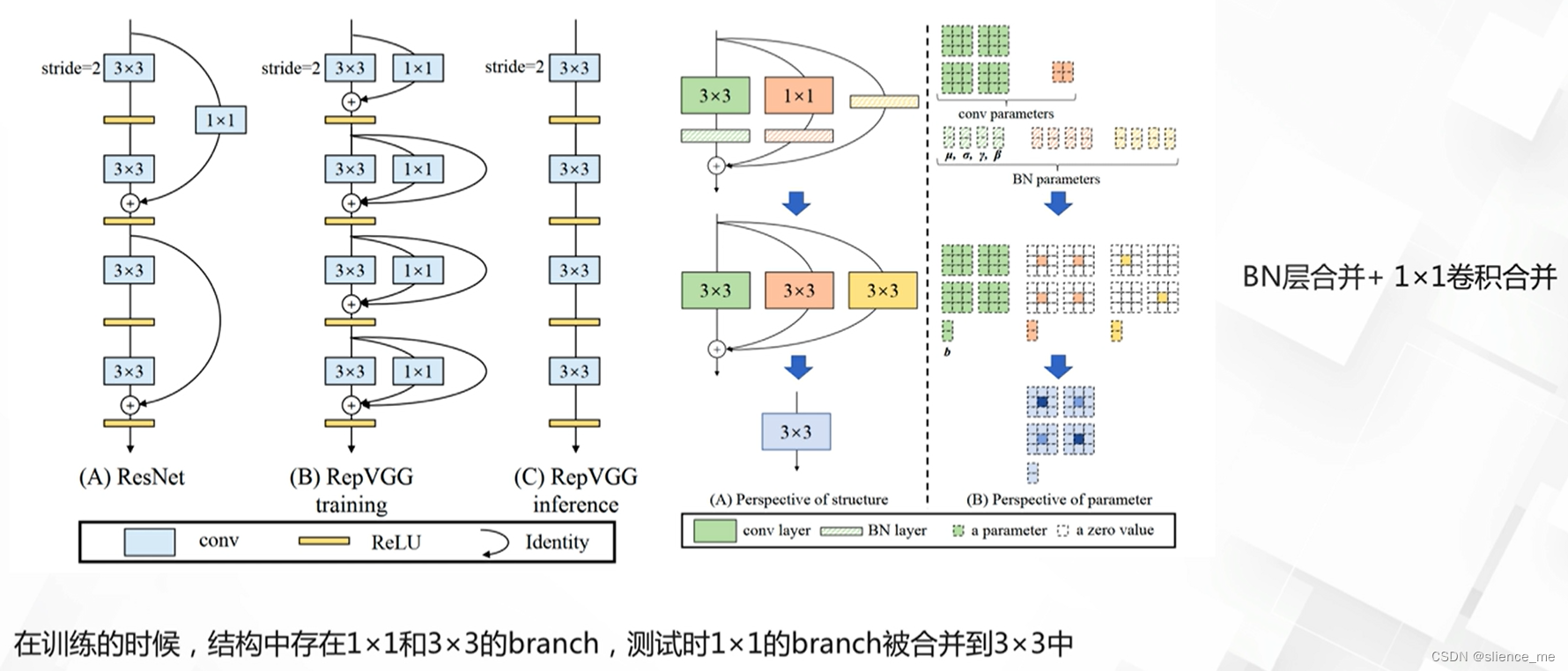
4.2 RepVGG
- <font color=#E91E63>训练时存在跳层连接,训练后合并连接</font>
注:部分内容来自阿里云天池