最优化
- 最优化是应用数学的一个分支,主要研究在特定情况下最大化或最小化某一特定函数或变量。
1. 最优化目标
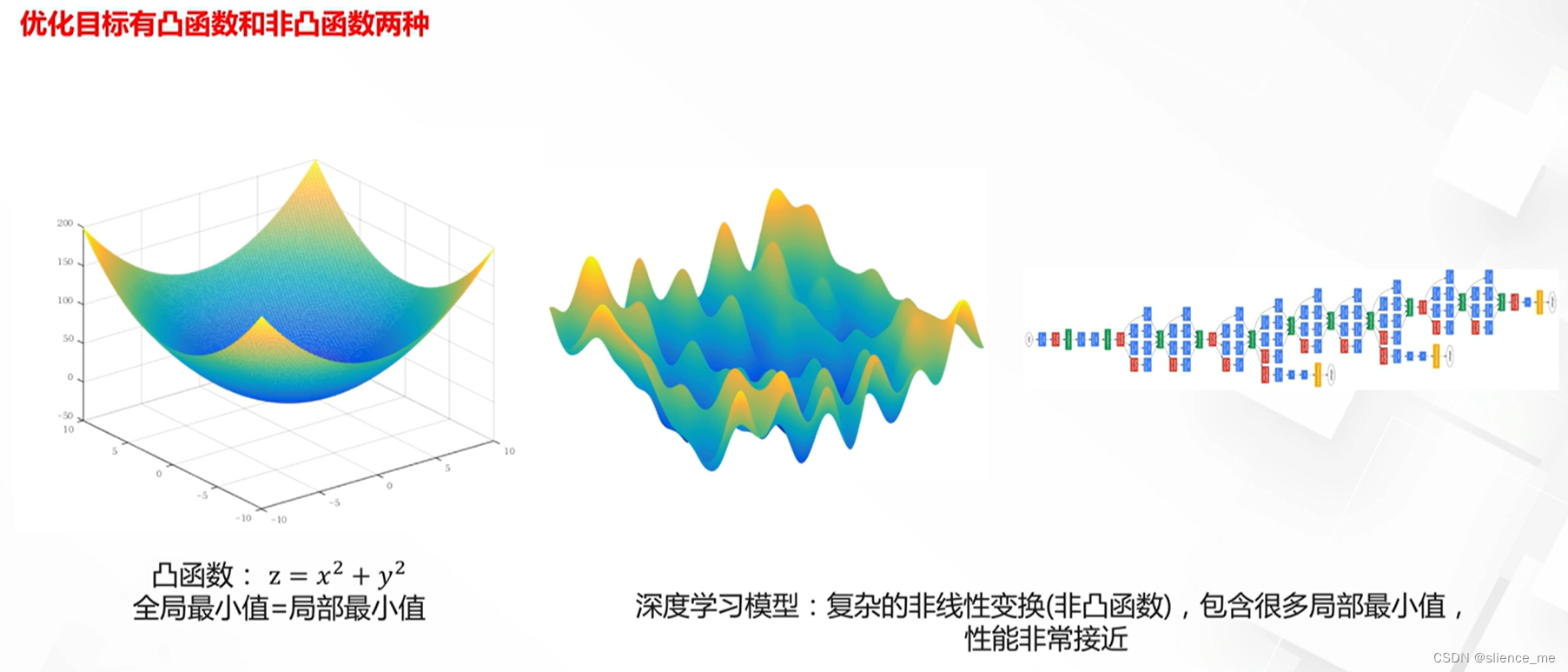
1.1 凸函数&凹函数
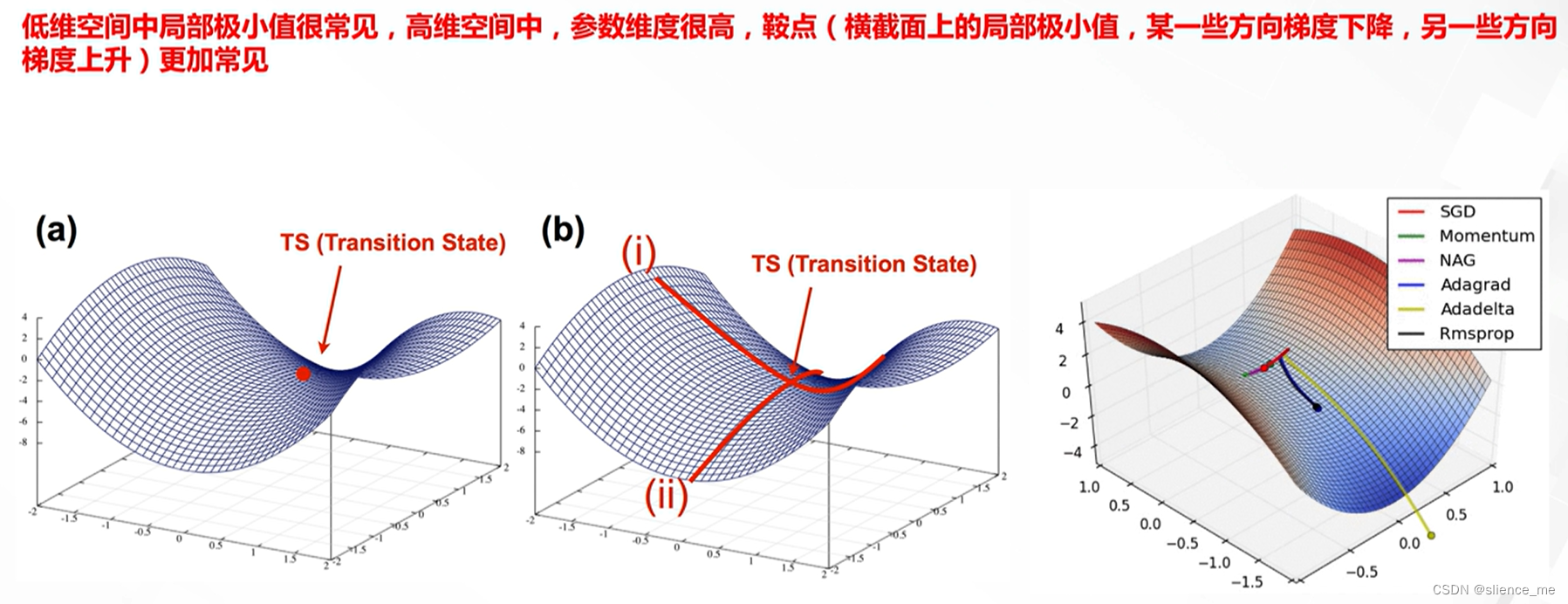
1.2 鞍点
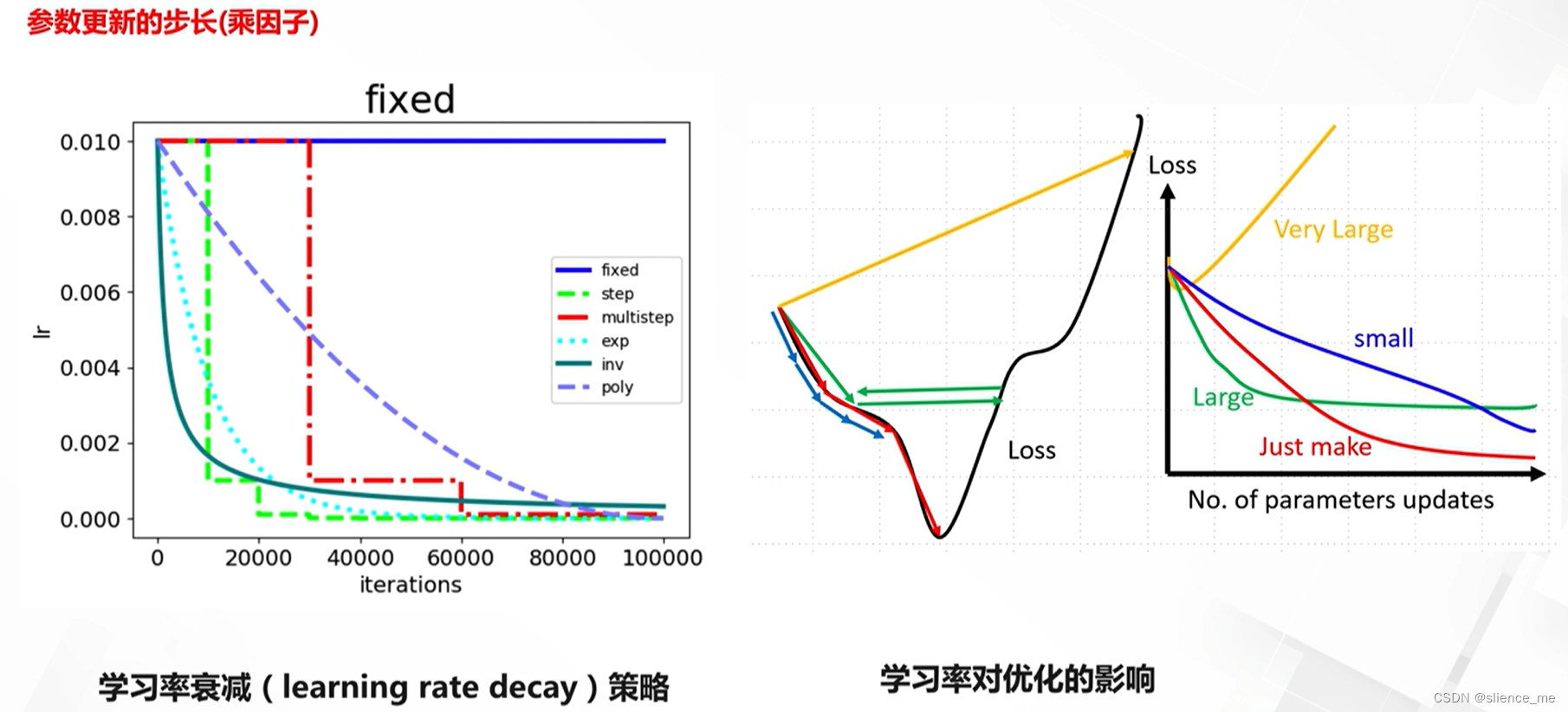
1.3 学习率
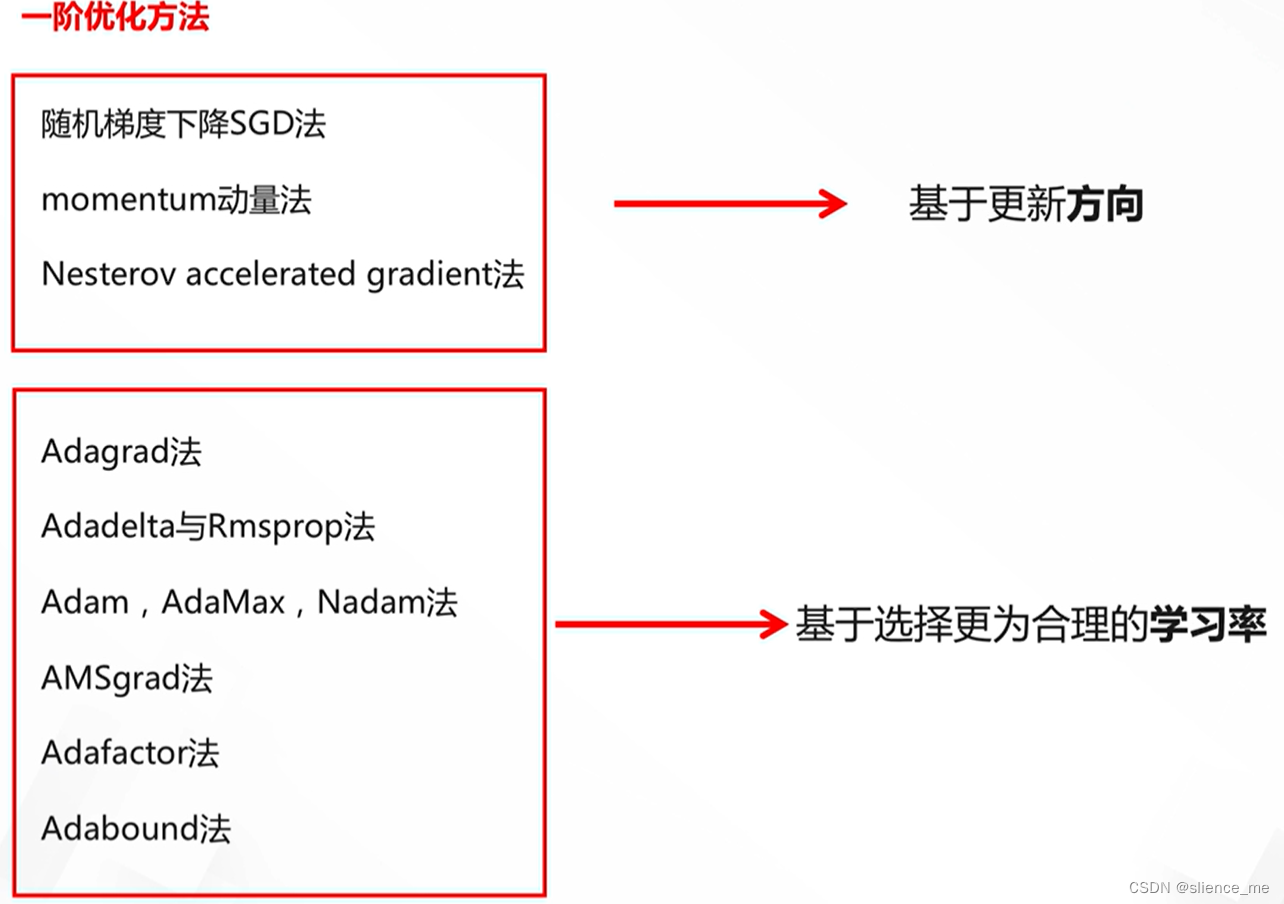
2. 常见的深度学习模型优化方法
深度学习模型的优化是训练深度神经网络的关键步骤,有多种方法可用于此目的。以下是一些常见的深度学习模型优化方法:
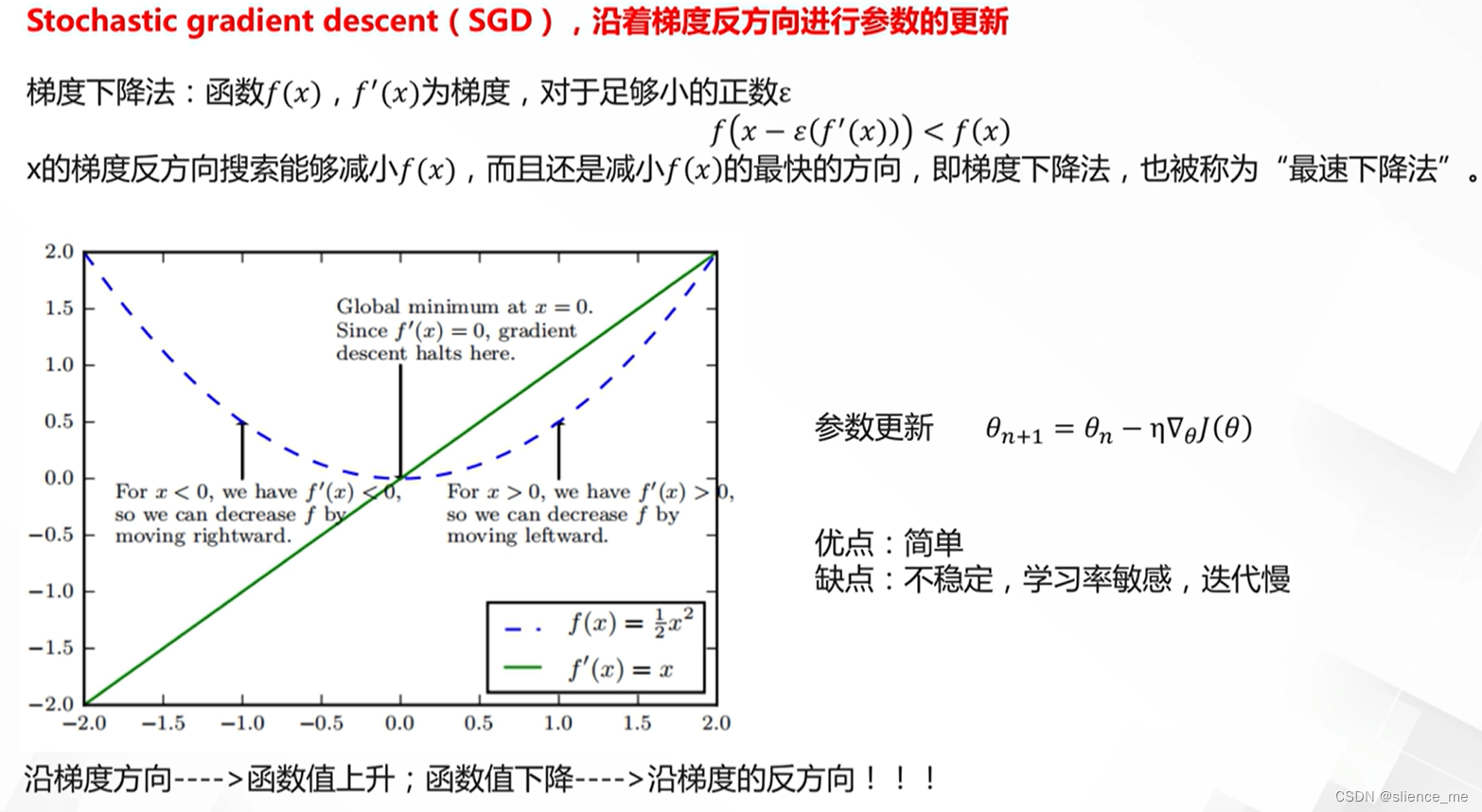
- 随机梯度下降(SGD):
- 操作:在每个迭代中,使用一小批训练样本来估计损失函数的梯度,并更新模型参数。
- 特点:SGD是深度学习中最常见的优化方法,具有较低的计算复杂性。
- 小批量梯度下降(Mini-batch GD):
- 操作:与SGD类似,但在每个迭代中使用多个训练样本来估计梯度。
- 特点:Mini-batch GD通常比SGD更稳定,并可通过调整批大小来平衡计算效率和收敛速度。
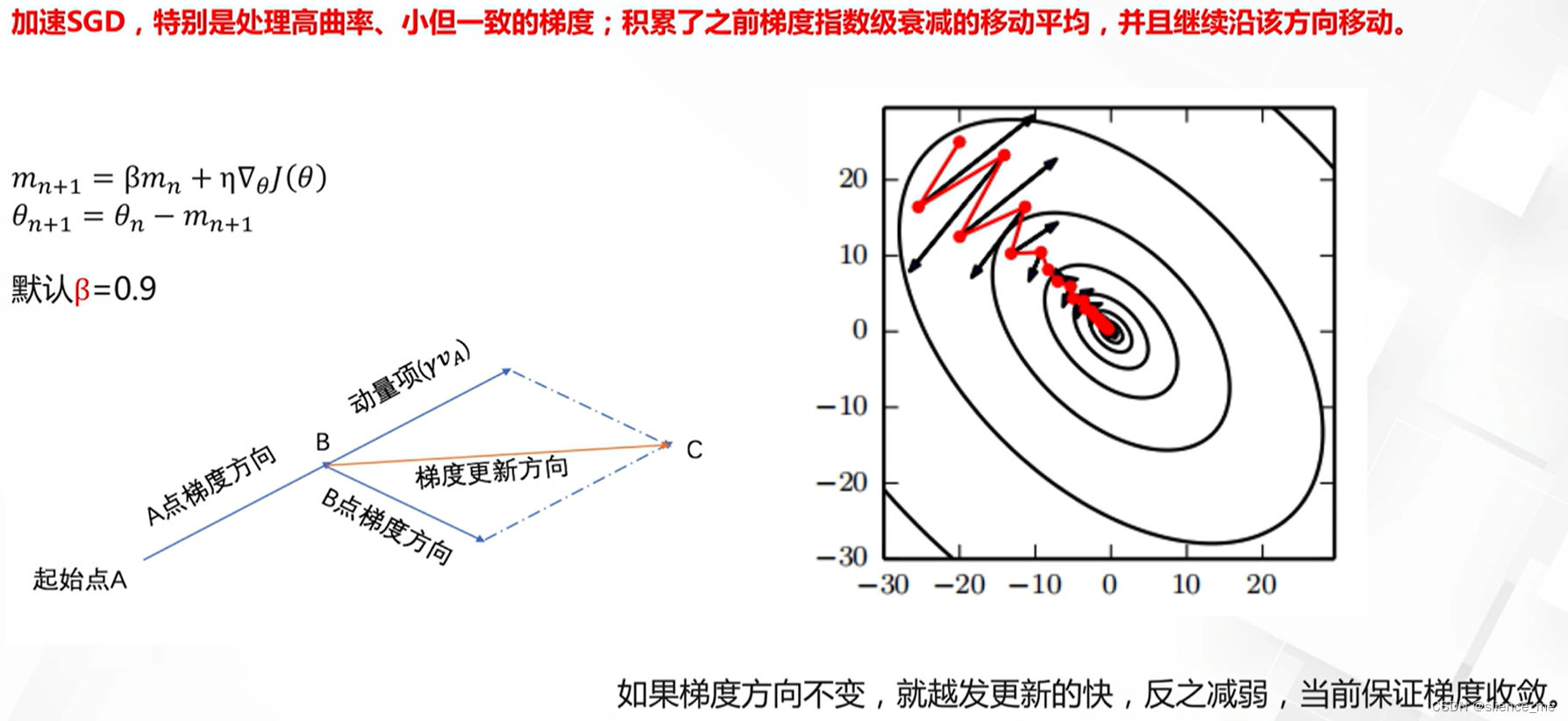
- 动量(Momentum):
- 操作:引入动量项,加速收敛,并减小梯度下降的震荡。
- 特点:动量有助于克服局部极小值,提高训练速度。
- AdaGrad:
- 操作:自适应地调整每个参数的学习率,使稀疏特征的学习率更大。
- 特点:AdaGrad适用于稀疏数据,但可能会随时间降低学习率。
- RMSprop:
- 操作:改进AdaGrad,引入指数移动平均来平滑学习率。
- 特点:RMSprop适用于非稀疏数据,提高了学习率的稳定性。
- Adam:
- 操作:结合动量和RMSprop,具有自适应学习率和动量调整。
- 特点:Adam通常表现出色,被广泛用于深度学习。
- Adadelta:
- 操作:类似于RMSprop,但不需要手动设置学习率。
- 特点:Adadelta自适应地调整学习率,无需调整超参数。
- Nadam:
- 操作:结合Nesterov动量和Adam的优点,同时考虑梯度和自适应学习率。
- 特点:Nadam通常具有较好的收敛性能。
- L-BFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno):
- 操作:使用L-BFGS等优化器来在每个迭代中直接优化损失函数。
- 特点:L-BFGS通常用于较小的数据集和较小的模型,具有较高的计算复杂性。
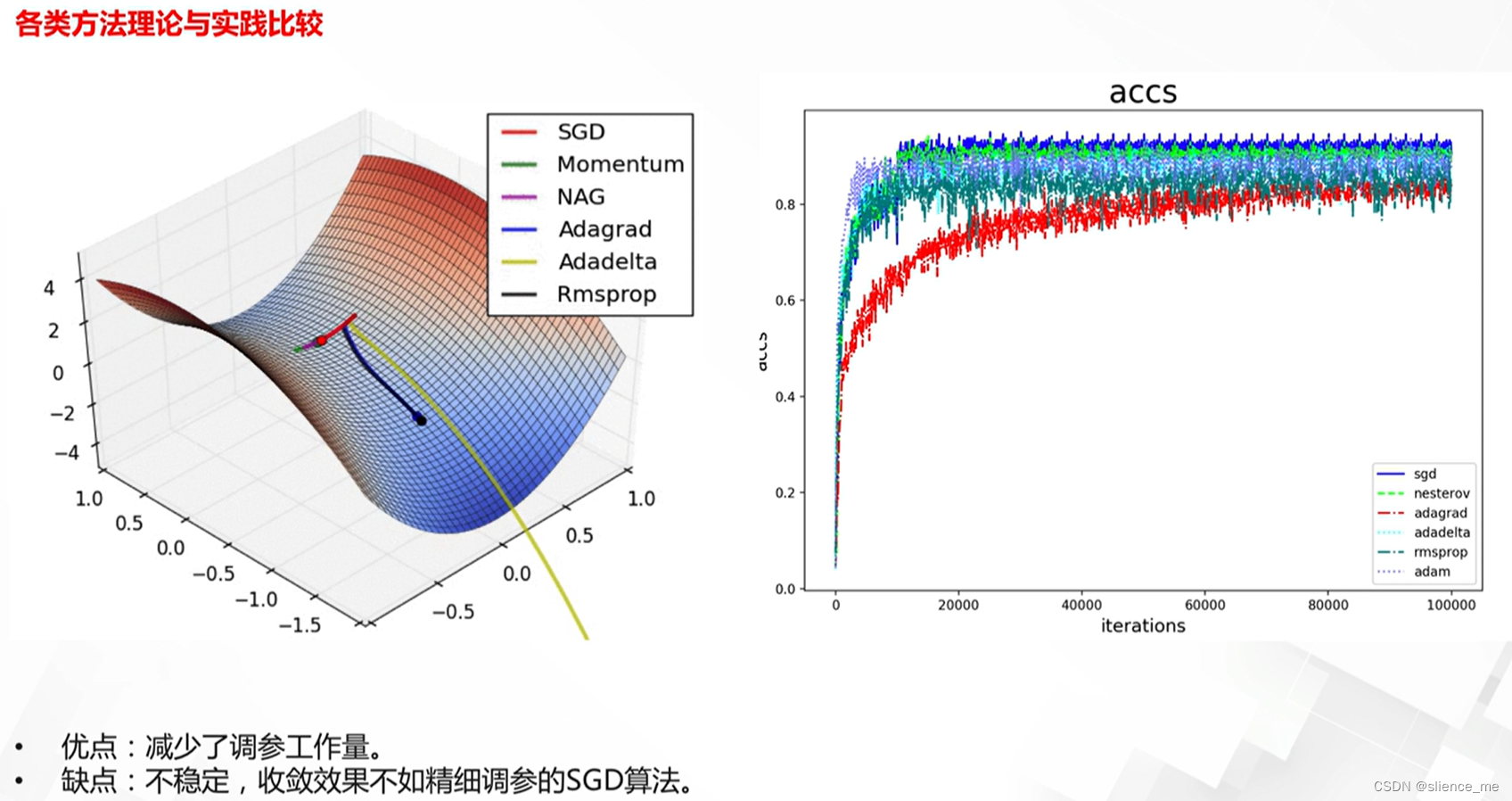
- 这些优化方法具有不同的性能和特点,适用于不同类型的深度学习任务。在实际应用中,通常需要根据任务、数据和模型来选择合适的优化方法,并进行超参数调整以获得最佳性能。
这些深度学习模型优化方法在不同方面存在区别和差异,包括学习率调整、收敛性、计算效率和适用性等。以下是它们的一些主要区别和差异:
- 学习率调整:
SGD:通常需要手动设置全局学习率,对学习率敏感。Momentum:引入动量项,加速收敛,但需要额外的动量超参数。AdaGrad:自适应地调整每个参数的学习率,但可能会导致学习率过小。RMSprop:改进AdaGrad,使用指数移动平均,减小学习率的不稳定性。Adam:结合动量和RMSprop,具有自适应学习率和动量,通常无需手动调整学习率。Adadelta:类似RMSprop,但无需手动设置学习率。Nadam:结合Nesterov动量和Adam,同时考虑梯度和自适应学习率。- 收敛性:
- 不同方法在收敛速度和稳定性上有所差异。Adam通常在训练速度和稳定性方面表现良好,而L-BFGS可能需要更多迭代以收敛。
- 计算效率:
- SGD和Mini-batch GD通常具有较低的计算复杂性,适用于大规模数据和模型。
- Adam等方法通常需要更多计算资源,但在训练速度上更具优势。
- 适用性:
- 不同方法适用于不同类型的问题。例如,Adadelta和Adagrad适用于稀疏数据,而Adam和Nadam通常适用于一般的深度学习任务。
- 超参数数量:
- 不同方法可能需要设置的超参数数量不同。SGD通常只需要设置全局学习率,而Adam和Nadam需要设置更多超参数。
- 收敛性能:
- 在不同问题上,不同方法可能具有不同的性能表现。通常需要进行实验来确定哪种方法对特定问题最有效。
- 总之,每种优化方法都有其优势和劣势,因此选择最佳的方法通常取决于具体的任务和问题。在深度学习中,通常需要进行超参数调整和实验来找到最适合特定任务的优化方法。
2.1 随机梯度下降法
2.2 动量法(Momentum)
2.3 Nesterov accelerated gradient法(NAG)

2.4 Adagrad法

2.5 Adadelta与Rmsprop法

2.6 Adam法

2.7 Adam算法的改进

3. SGD的改进算法一定会更好吗?
4. 二阶优化算法为何不用?

注意:部分内容来自 阿里云天池