泛化与正则化
1. 泛化(generalization)
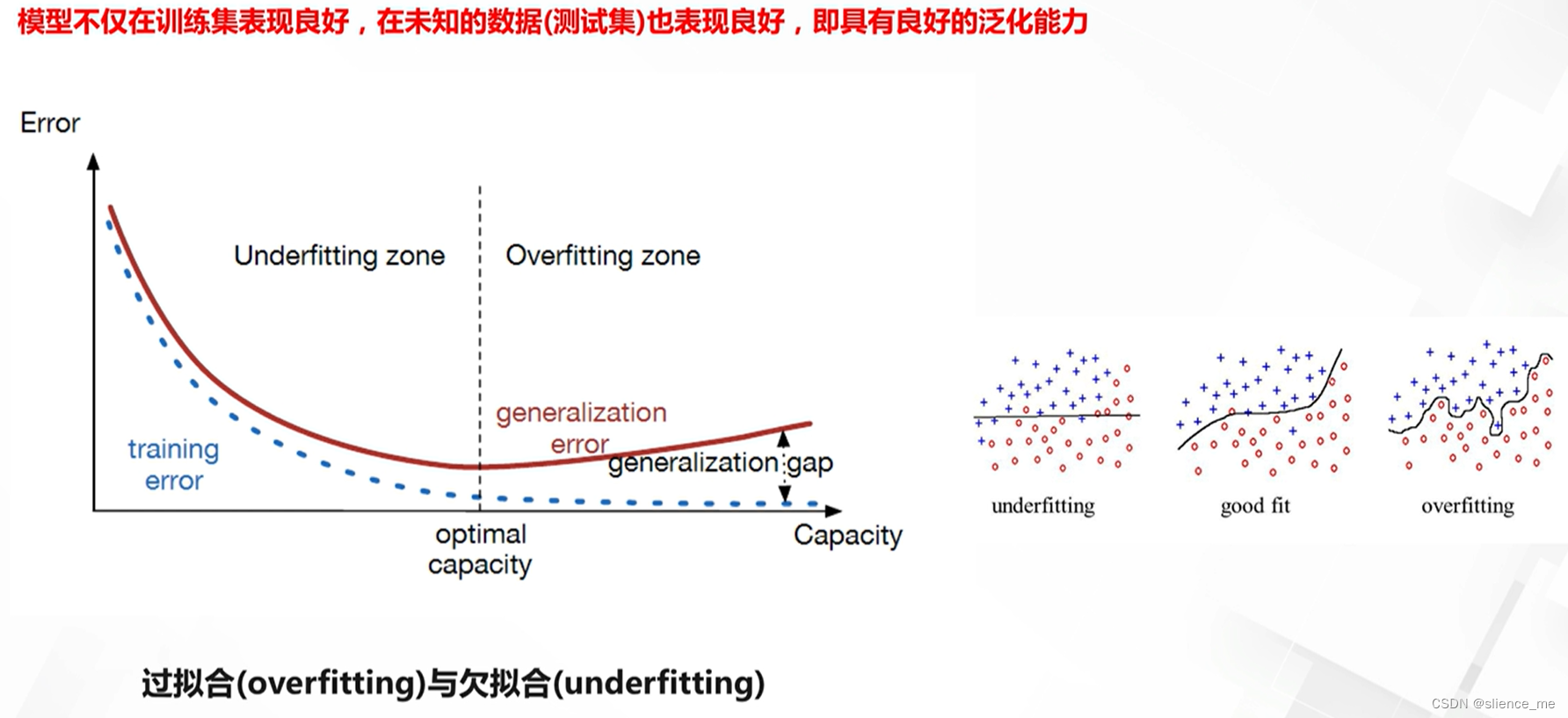
泛化不好可能带来的问题
- 模型性能不稳定
- 容易受到攻击

2. 正则化方法
提高泛化能力
2.1 显式正则化方法
显式正则化方法对比
显式正则化是一种用于
减少过拟合风险的技术,通过在损失函数中引入附加项来限制模型的复杂性。以下是一些常见的显式正则化方法:
- L1正则化(Lasso正则化):
- 目标:最小化损失函数的同时,最小化模型参数的绝对值之和。
- 效果:L1正则化鼓励模型具有稀疏性,某些参数变为零,从而实现特征选择。
- L2正则化(Ridge正则化):
- 目标:最小化损失函数的同时,最小化模型参数的平方之和。
- 效果:L2正则化有助于防止模型参数过大,减少过拟合风险。
- 弹性网络(Elastic Net正则化):
- 目标:综合L1正则化和L2正则化,以平衡特征选择和模型参数缩减。
- 效果:弹性网络结合了L1和L2的优点,适用于多重共线性问题。
- Dropout:
- 操作:在训练过程中,以一定概率随机将神经元设置为零。
- 效果:Dropout有助于减少神经网络的过拟合,增加模型的鲁棒性。
- 权重衰减(Weight Decay):
- 目标:在损失函数中添加一个惩罚项,降低参数的绝对值。
- 效果:权重衰减有助于限制模型的复杂性,减少过拟合。
- 正交正则化:
- 目标:鼓励模型参数矩阵的列之间正交,以减少参数之间的相关性。
- 效果:正交正则化有助于解决多重共线性问题,改善模型的稳定性。
- 知识蒸馏(Knowledge Distillation):
- 目标:在训练时,通过学习来自教师模型的软标签,来约束学生模型。
- 效果:知识蒸馏有助于改善模型的泛化性能和鲁棒性。
- 核正则化:
- 目标:对核矩阵施加正则化以降低复杂性。
- 效果:核正则化有助于防止支持向量机等模型的过拟合。
这些显式正则化方法都旨在通过不同方式限制模型的复杂性,以减少过拟合的风险。选择适当的正则化方法通常取决于特定的问题和数据。
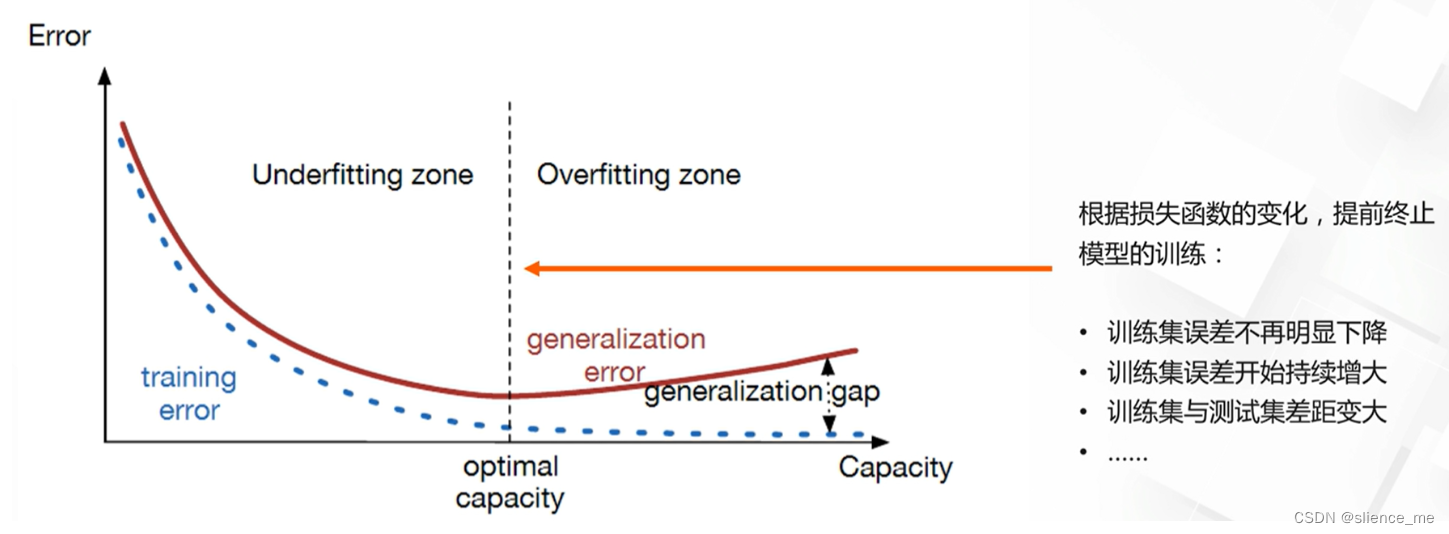
提前终止模型的训练
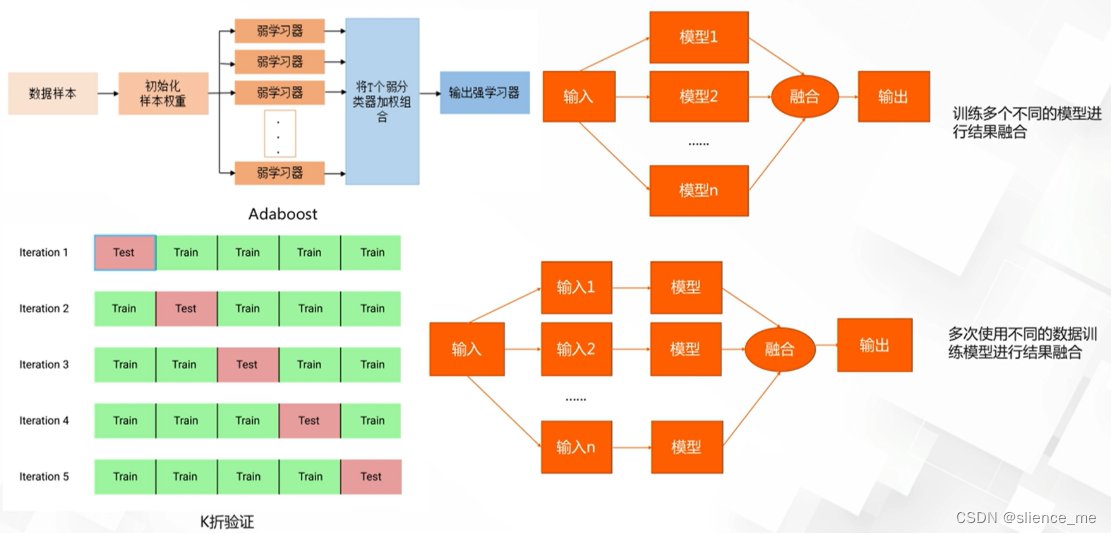
多个模型集成
Dropout技术
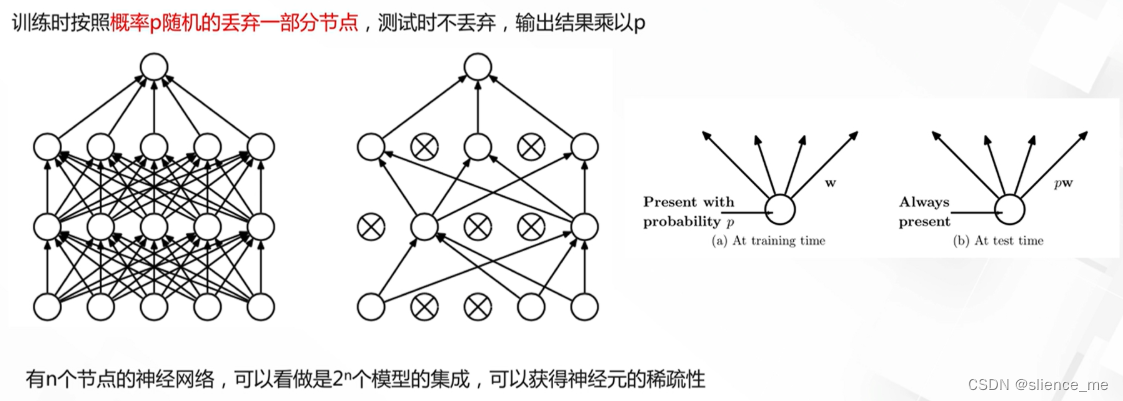
Dropout技术对模型的影响 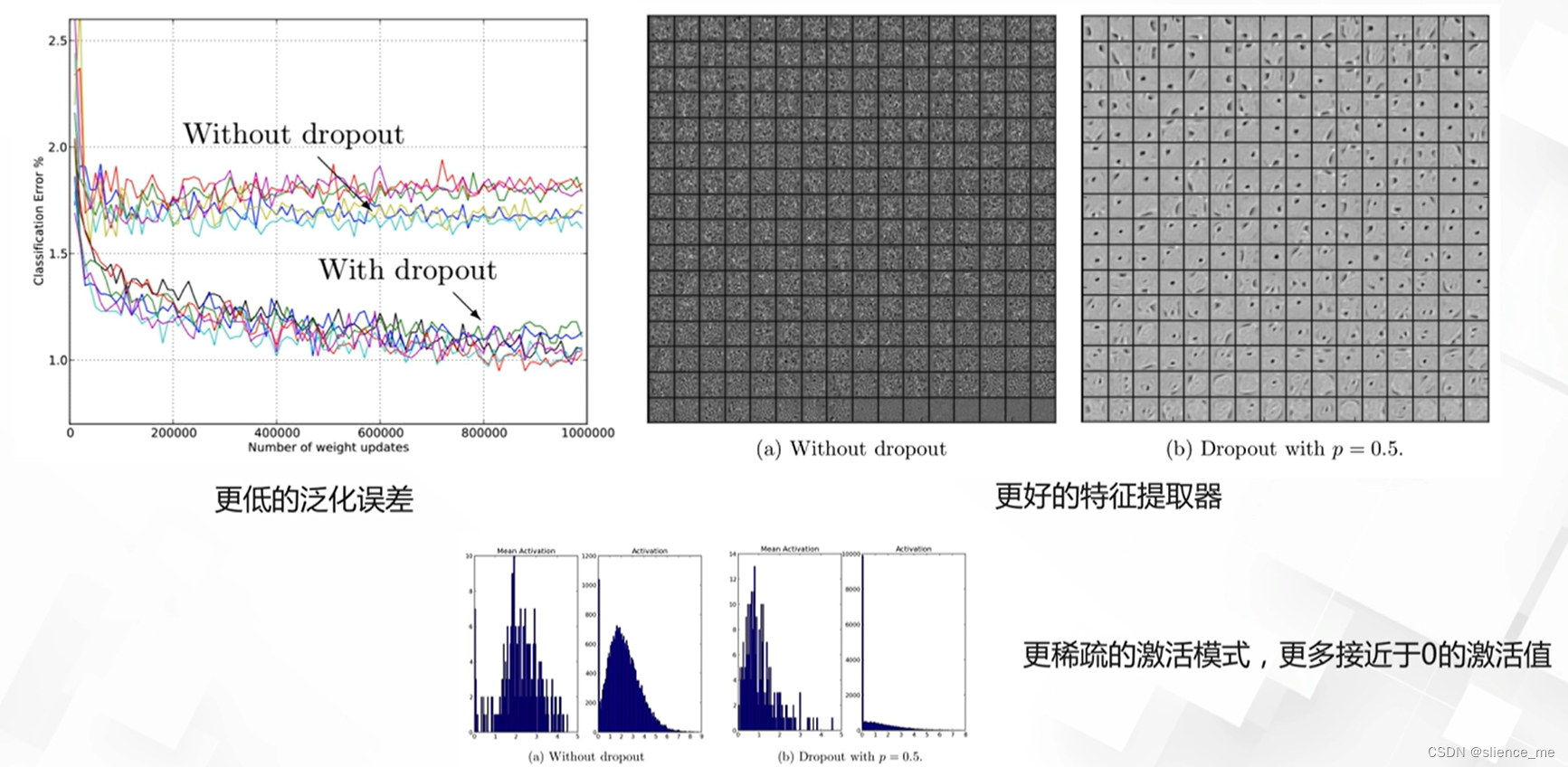
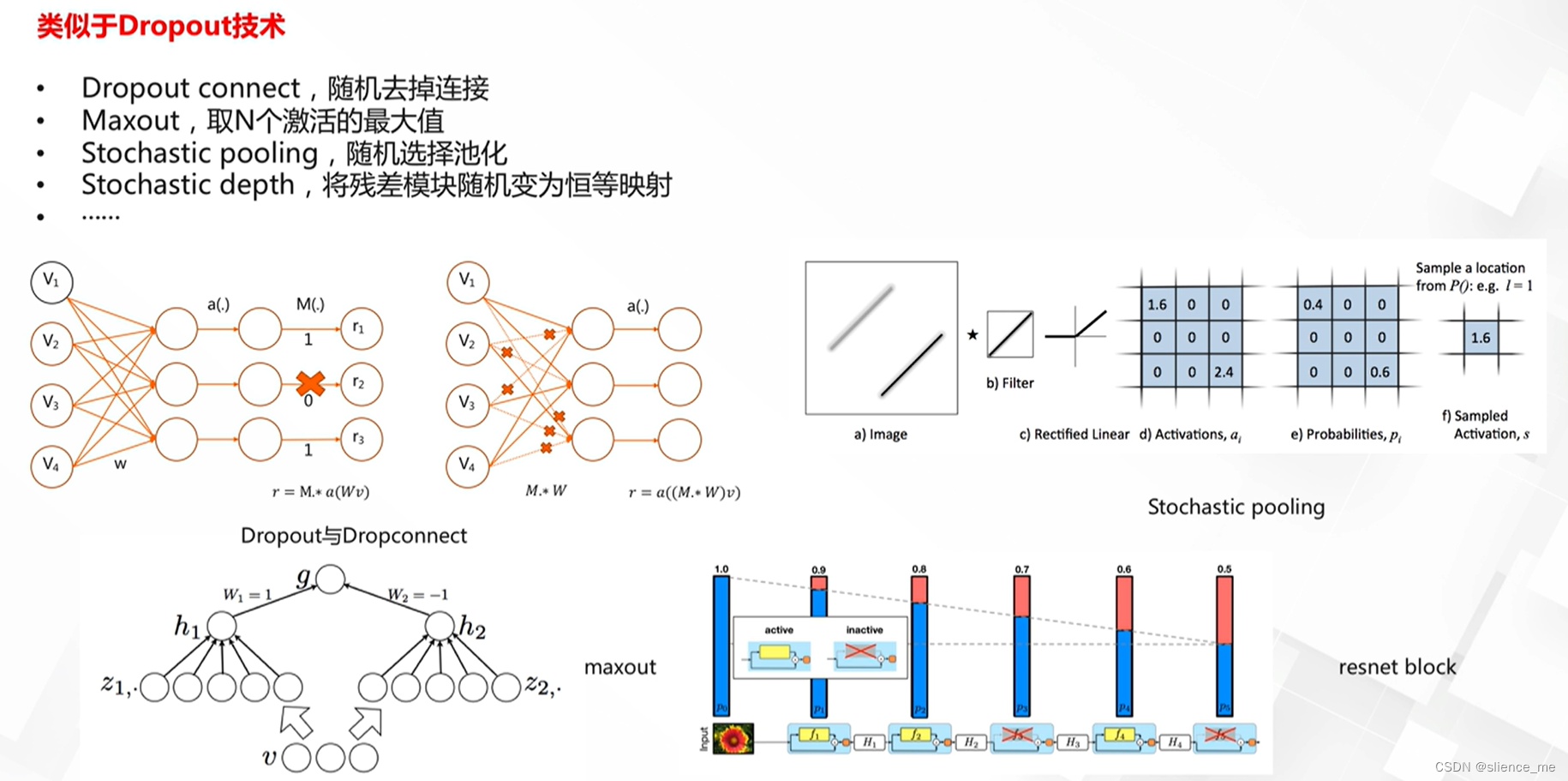
2.2 参数正则化方法
损失函数的更改 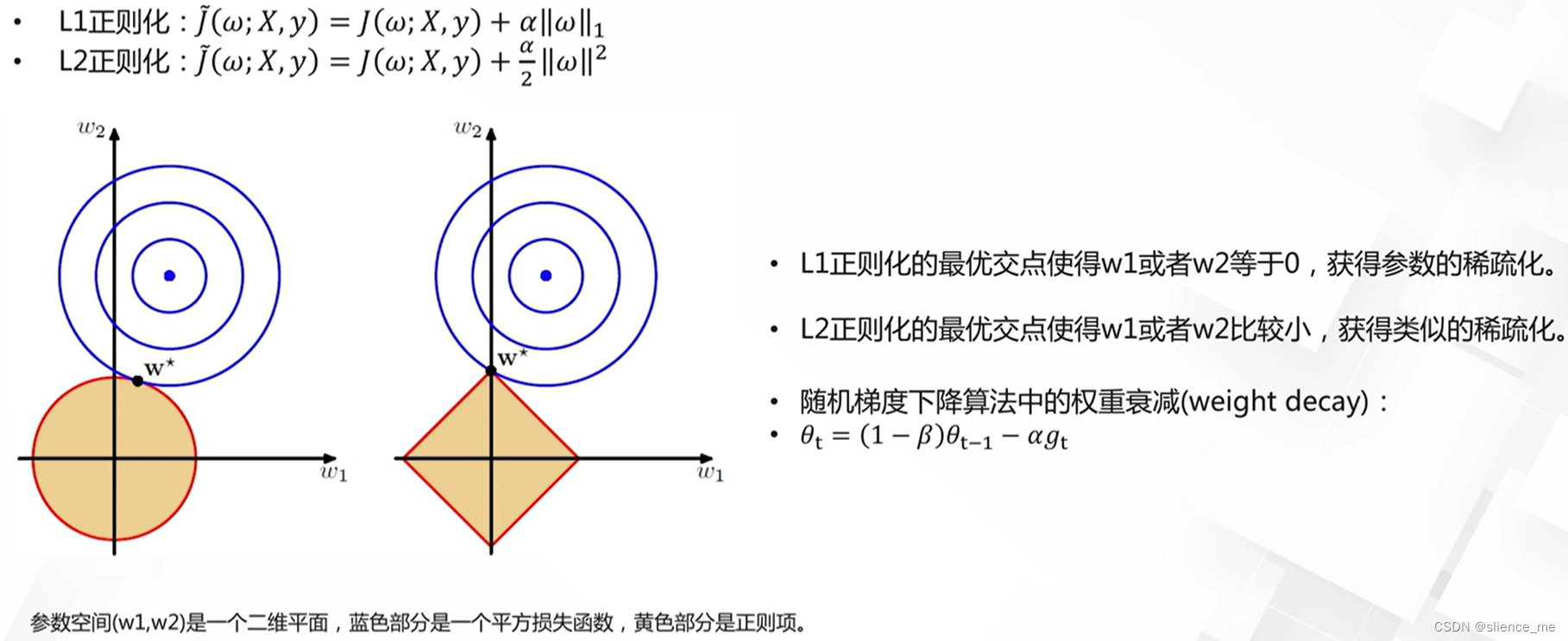
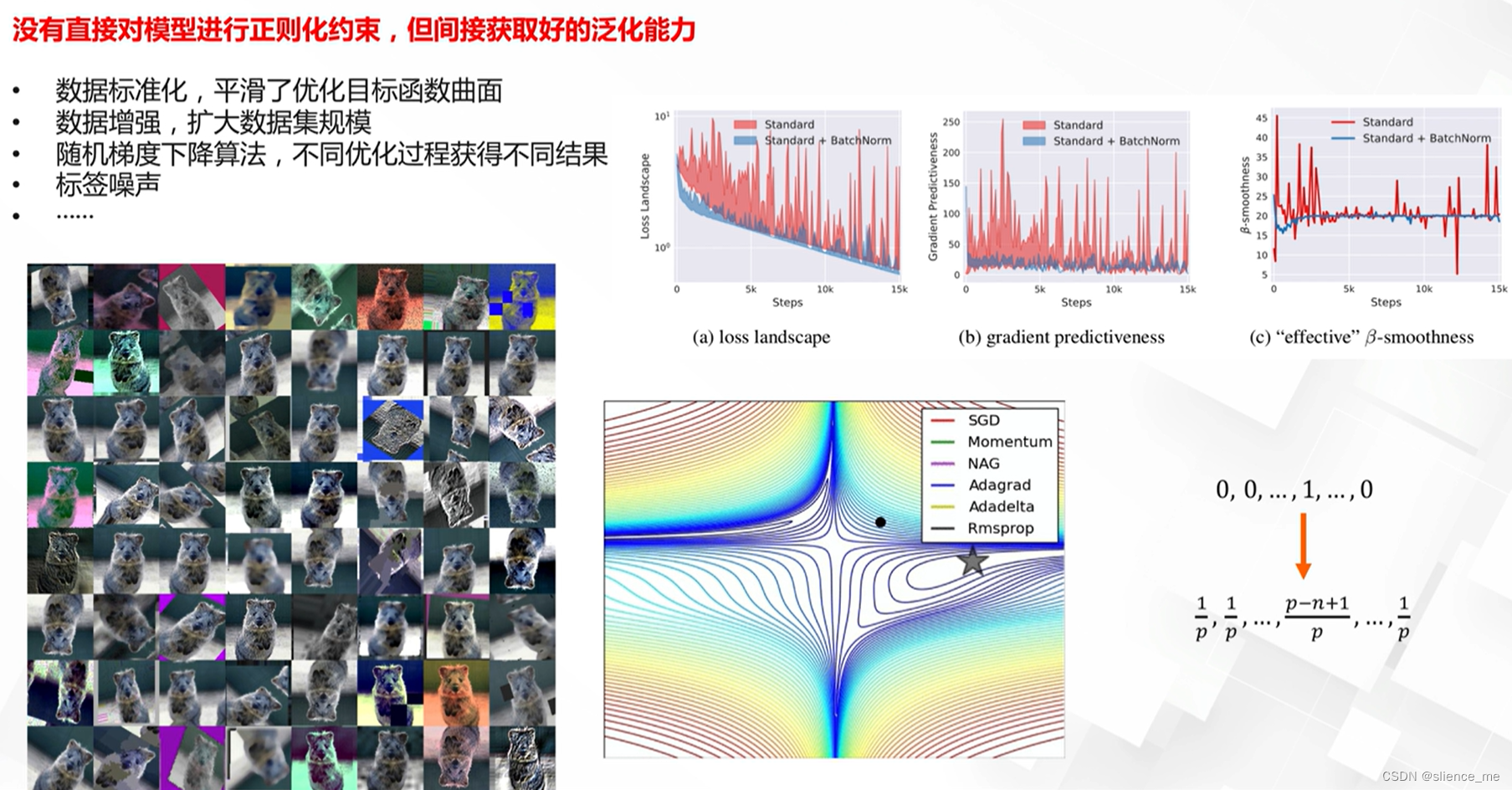
2.3 隐式正则化方法
方法对比
隐式正则化是指在训练深度神经网络时,通过网络结构、数据增强等隐含方式降低模型的过拟合风险。以下是一些常见的隐式正则化方法:
- 数据增强:
- 操作:通过对训练数据进行随机变换,如旋转、翻转、剪裁等,增加数据样本的多样性。
- 效果:数据增强有助于提高模型的泛化性能,降低对特定数据分布的依赖。
- 早停(Early Stopping):
- 操作:在训练过程中监测验证集上的性能,当性能不再提升时停止训练。
- 效果:早停有助于防止模型在训练数据上过分拟合,促使模型更早地停止学习。
- 梯度裁剪(Gradient Clipping):
- 操作:限制梯度的大小,以防止梯度爆炸问题。
- 效果:梯度裁剪有助于提高模型的稳定性,防止过度学习。
- 参数共享:
- 操作:在网络的某些层中共享参数,减少模型参数数量。
- 效果:参数共享有助于减小模型的复杂性,降低过拟合风险。
- 权重初始化:
- 操作:合适的权重初始化方法有助于更好地训练深度网络。
- 效果:权重初始化可以影响网络的收敛速度和性能。
这些隐式正则化方法通过对网络结构和训练过程的调整来减少过拟合风险,而无需明确引入正则化项。选择合适的隐式正则化方法通常取决于具体的任务和网络架构。
文档信息
- 本文作者:slience_me
- 本文链接:https://slienceme.xyz/2023/10/24/%E6%B3%9B%E5%8C%96%E4%B8%8E%E6%AD%A3%E5%88%99%E5%8C%96%E5%90%88%E9%9B%86/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)