标准化与池化
1. 标准化/归一化
1.1 归一化

归一化的作用
- 去除量纲的干扰,防止数值过小的特征被淹没
- 保证数据的有效性
- 稳定数据分布

1.2 标准化
批标准化方法 Batch Normailzation
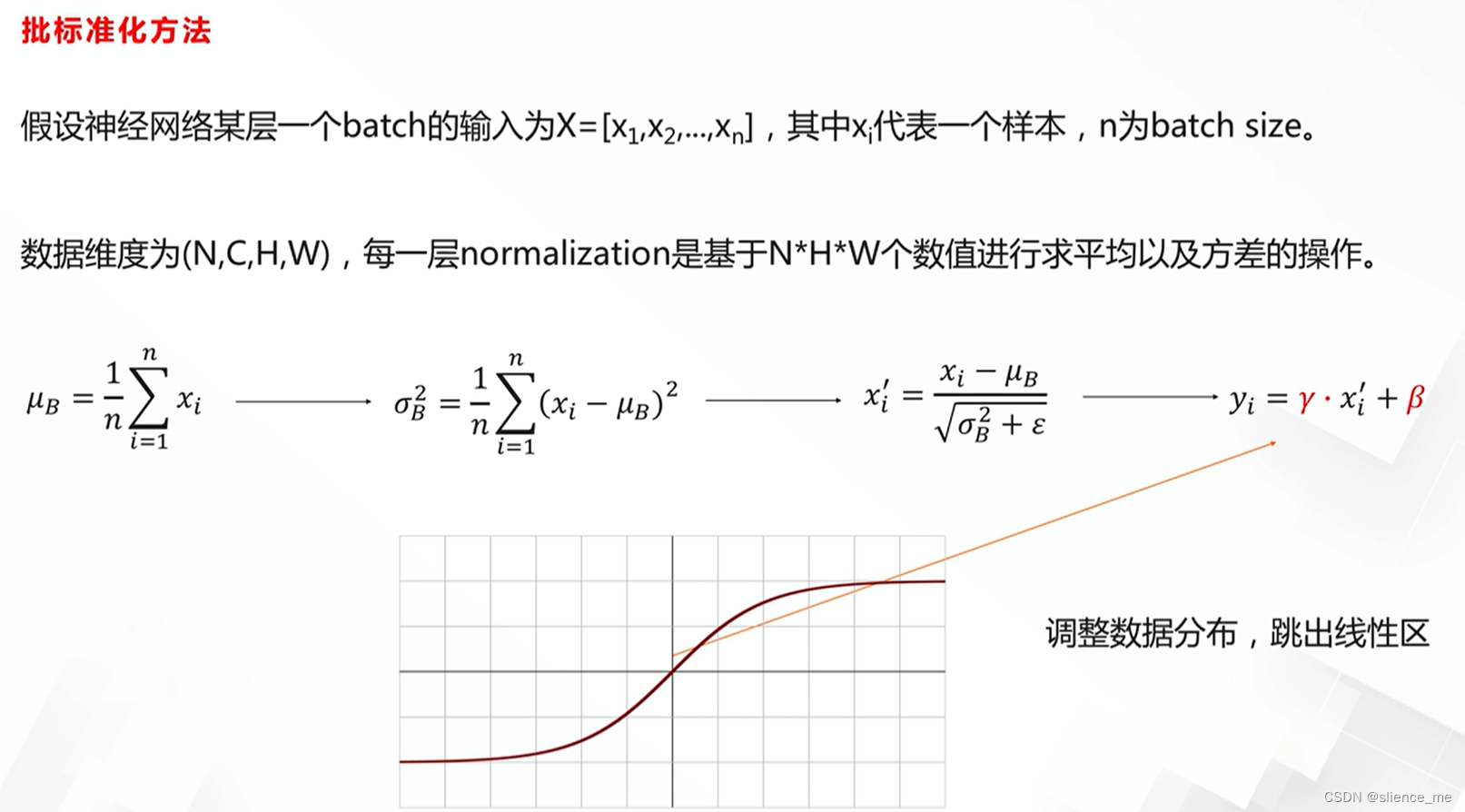
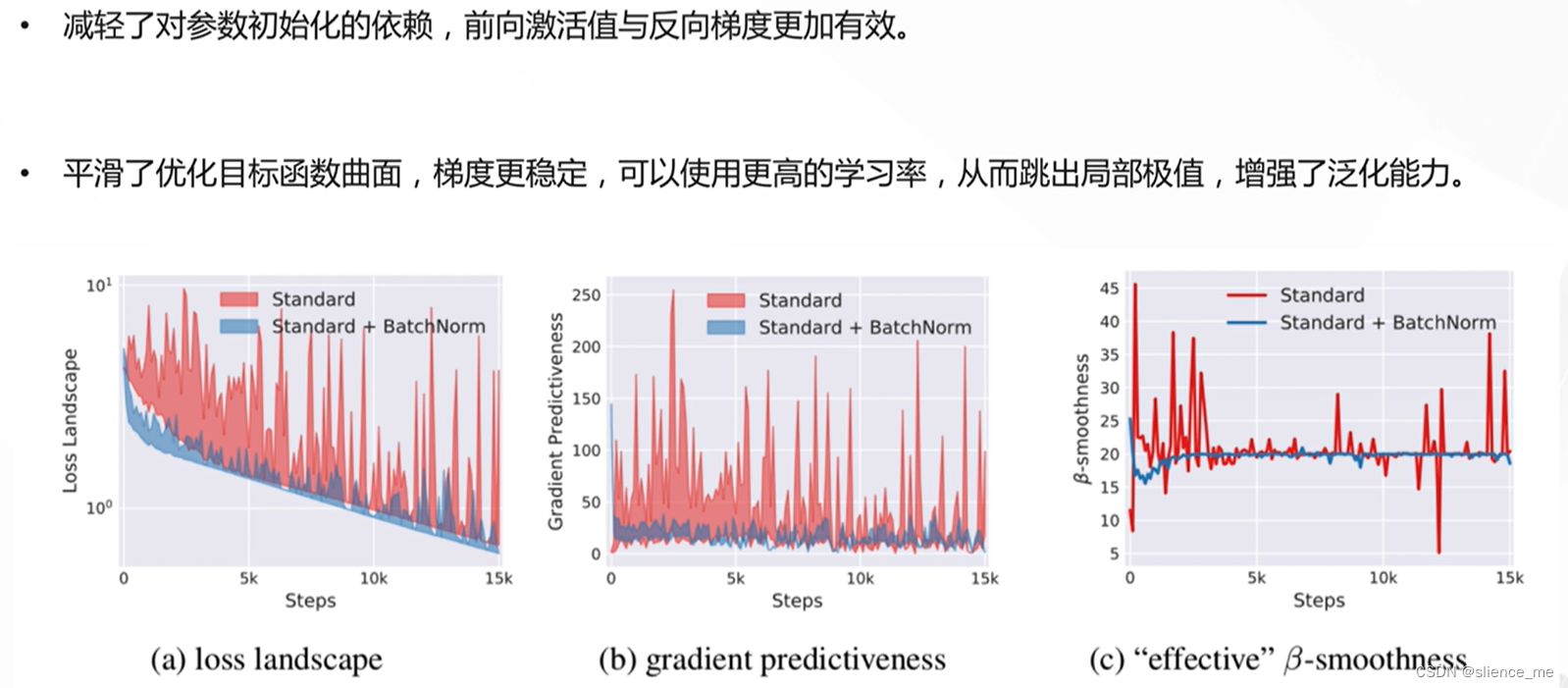
批标准化的好处
- 提高训练速度
- 稳定模型训练
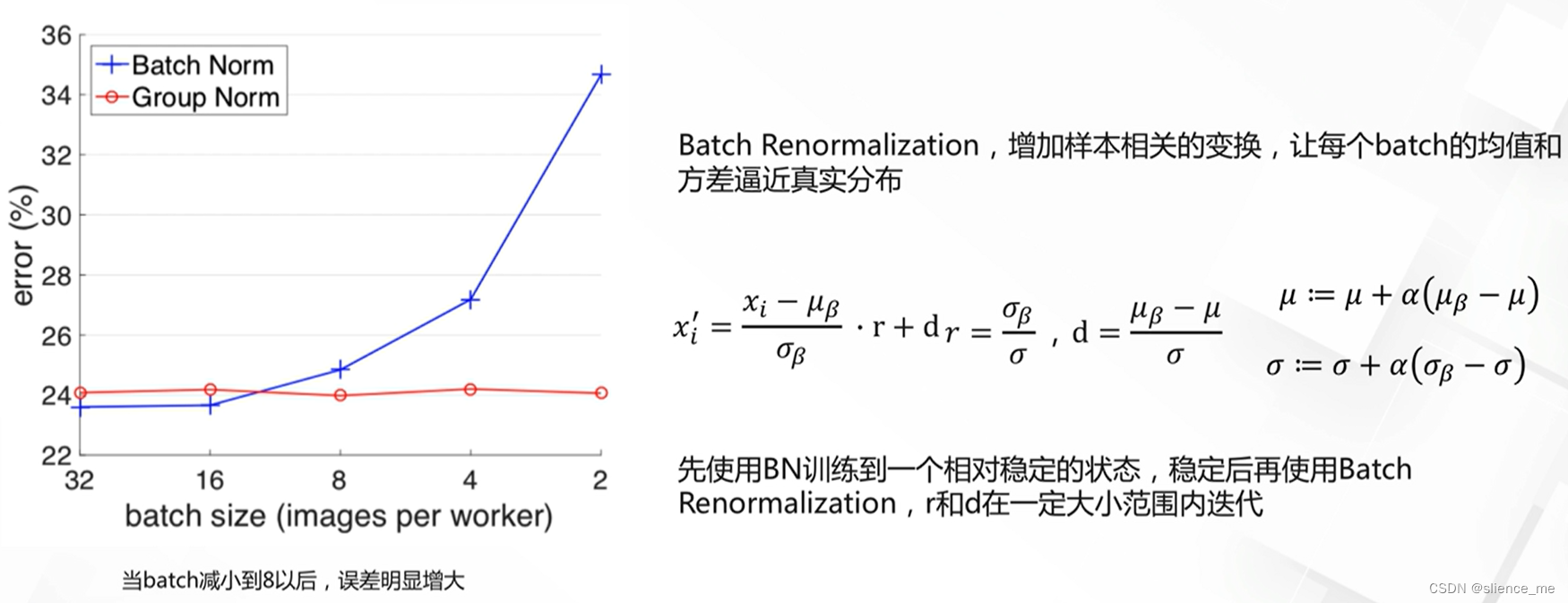
批标准化的缺点与改进
- 要求固定的Batch长度与均匀采样
- batch过小数值计算不稳定
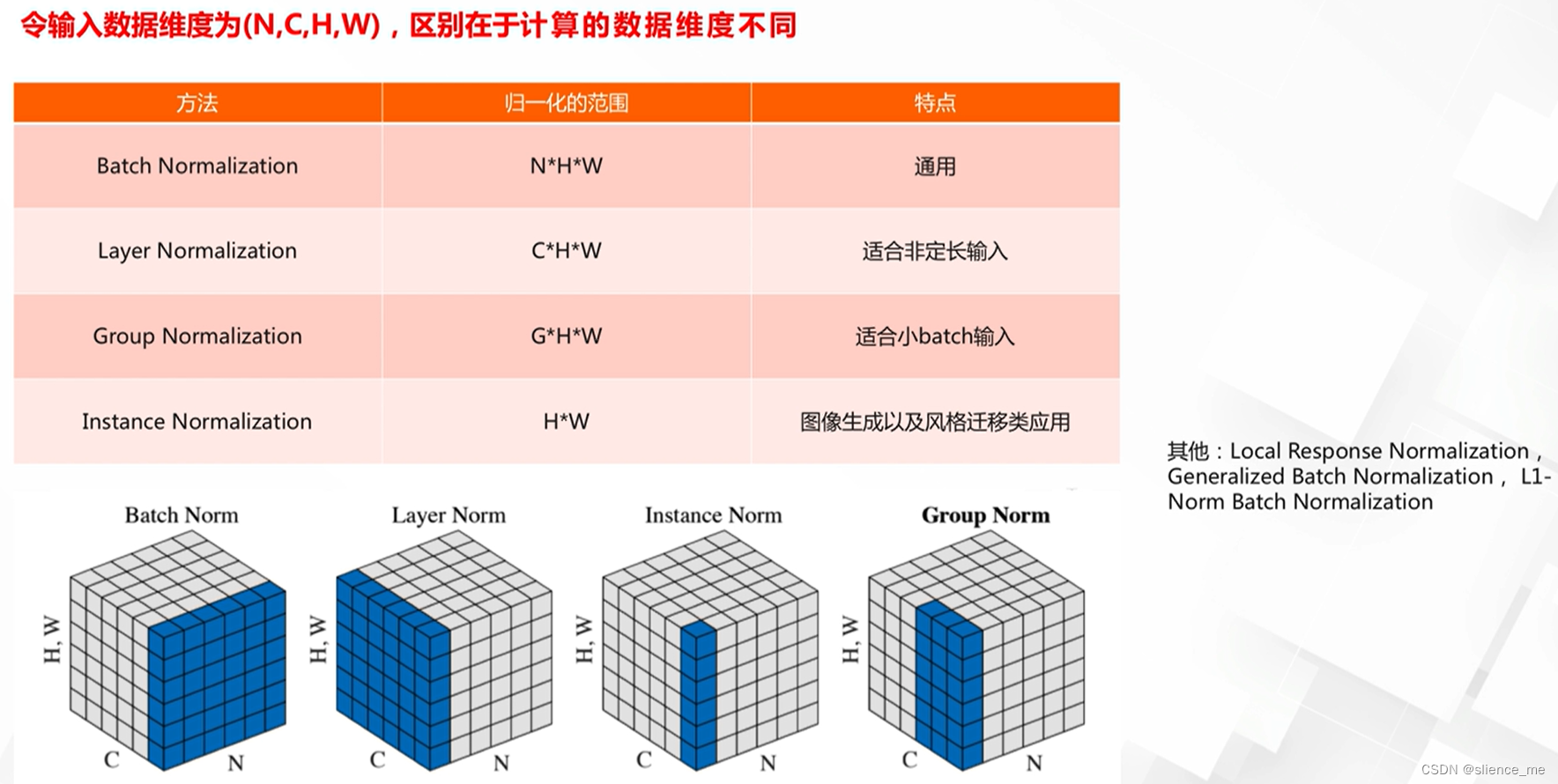
标准化方法的对比
Batch Normalization(批标准化)、Layer Normalization(层标准化)、Group Normalization(组标准化)、Instance Normalization(实例标准化)都是用于深度神经网络的归一化技术,用于改善训练的稳定性和收敛速度。它们在归一化的对象和方式上有一些不同之处:
Batch Normalization(批标准化):
- 归一化对象:Batch Normalization是在每个神经层的输入上进行归一化,通常是对每个mini-batch的样本进行统计。
- 归一化方式:它通过计算每个神经元的均值和方差,然后对每个神经元的输出进行归一化,以确保网络的中间层保持稳定。
Layer Normalization(层标准化):
- 归一化对象:Layer Normalization是在每个神经层的输入上进行归一化,但不考虑mini-batch内的样本,而是考虑单层的所有神经元。
- 归一化方式:它通过计算每个神经元的均值和方差,然后对单层内的所有神经元的输出进行归一化。
Group Normalization(组标准化):
- 归一化对象:Group Normalization是在每个神经层的输入上进行归一化,但不是针对整个层或整个mini-batch,而是将神经元分成多个组,然后对每个组内的神经元进行归一化。
- 归一化方式:它通过计算每个组内神经元的均值和方差,然后对每个组内的神经元的输出进行归一化。
Instance Normalization(实例标准化):
- 归一化对象:Instance Normalization是在每个神经元的输入上进行归一化,针对每个神经元的输出进行归一化,而不考虑层内、mini-batch内的其他神经元。
- 归一化方式:它通过计算每个神经元的均值和方差,然后对每个神经元的输出进行归一化。
总的来说,这些归一化方法都有类似的目标,即减少内部协变量偏移(Internal Covariate Shift)以提高深度神经网络的训练稳定性和收敛速度。它们的不同之处在于归一化的对象和方式。选择哪种归一化方法通常取决于网络的结构、任务和实验表现。 Batch Normalization通常用于深度卷积神经网络中,而Layer Normalization、Group Normalization和Instance Normalization可能更适用于其他类型的网络或特定的任务。
当涉及到Batch Normalization(批标准化)、Layer Normalization(层标准化)、Group Normalization(组标准化)、Instance Normalization(实例标准化)时,它们之间的差异在于归一化的对象和方式。下面是一个图示示例,以帮助理解它们的区别:
Batch Normalization (BN) Layer Normalization (LN) Group Normalization (GN) Instance Normalization (IN) _______________ _______________ _______________ _______________ | Layer 1 | | Layer 1 | | Layer 1 | | Layer 1 | | --------------| | --------------| | --------------| | --------------| | Neuron 1 | | Neuron 1 | | Group 1 | | Neuron 1 | | Neuron 2 | | Neuron 2 | | Group 2 | | Neuron 2 | | Neuron 3 | | Neuron 3 | | Group 3 | | Neuron 3 | | ... | | ... | | ... | | ... | | Neuron N | | Neuron N | | Group N | | Neuron N | | --------------| | --------------| | --------------| | --------------| | Layer 2 | | Layer 2 | | Layer 2 | | Layer 2 | | --------------| | --------------| | --------------| | --------------| | Neuron 1 | | Neuron 1 | | Group 1 | | Neuron 1 | | Neuron 2 | | Neuron 2 | | Group 2 | | Neuron 2 | | Neuron 3 | | Neuron 3 | | Group 3 | | Neuron 3 | | ... | | ... | | ... | | ... | | Neuron N | | Neuron N | | Group N | | Neuron N | | _______________| | _______________| | ______________| | ______________|
- Batch Normalization:每个层内的神经元在整个mini-batch中进行归一化。
- Layer Normalization:每一层的神经元在层内进行归一化,但不考虑mini-batch内的样本。
- Group Normalization:每一层的神经元被分成多个组,每个组内的神经元进行归一化,不考虑mini-batch内的样本。
- Instance Normalization:每个神经元单独进行归一化,不考虑层内、mini-batch内的其他神经元。
这个示例说明了它们之间在归一化对象和方式上的区别,希望有助于理解它们的工作原理。这些方法都是用于改善神经网络训练的稳定性和收敛速度,但在不同情况下选择适当的方法可能会有所不同。
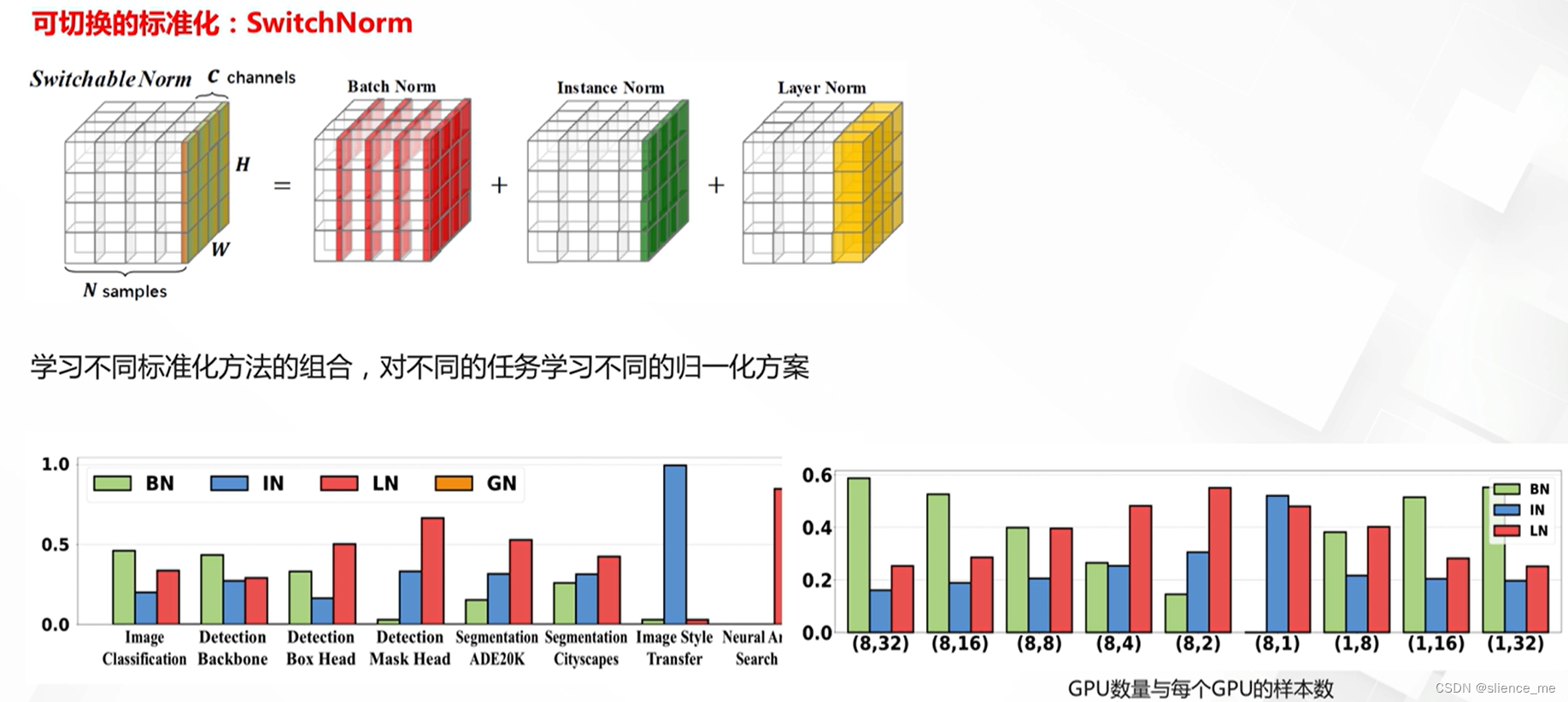
自动学习标准化方法
2. 池化
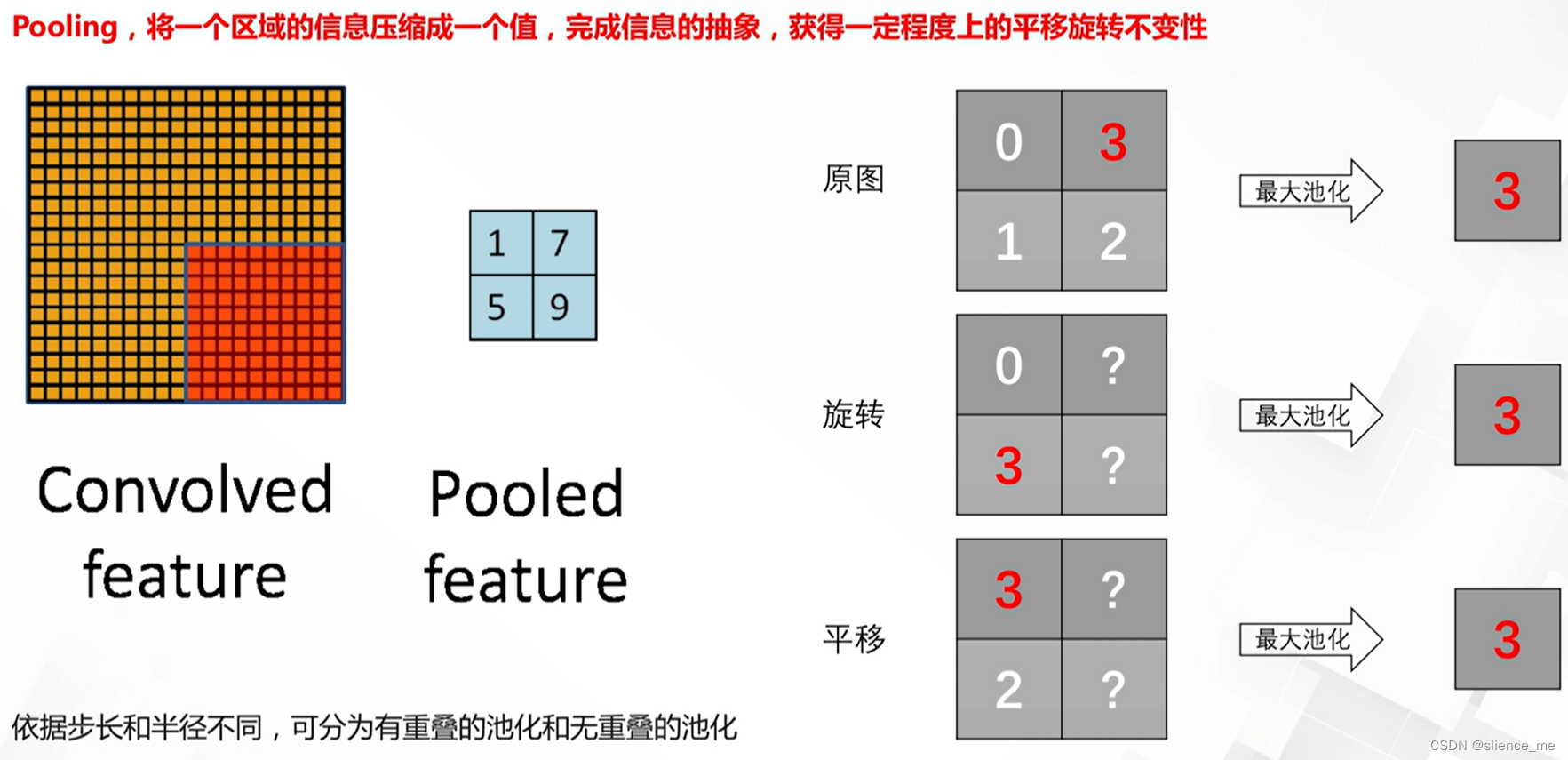
2.1 池化的作用
作用:
- 信息的抽象,去除非细节部分一些噪声的信息
- 获得不同程度上的不变性:旋转不变性,平移不变性
2.2 常见的池化方法
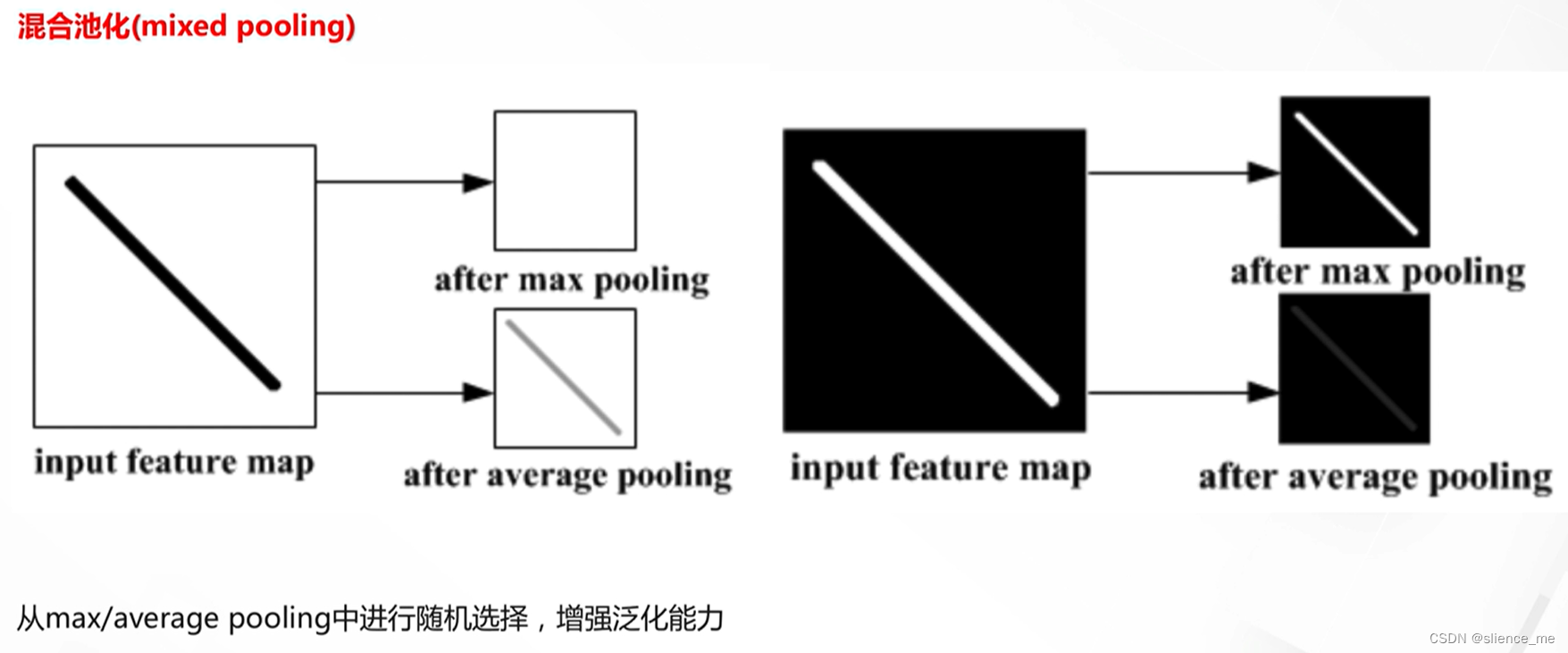
2.3 池化方法的差异
不同的池化方法是用来降低特征图维度的方式,它们在计算输出时有不同的策略。以下是最大值池化、均值池化、随机池化、最小值池化、中值池化和混合池化等池化方法之间的主要区别:
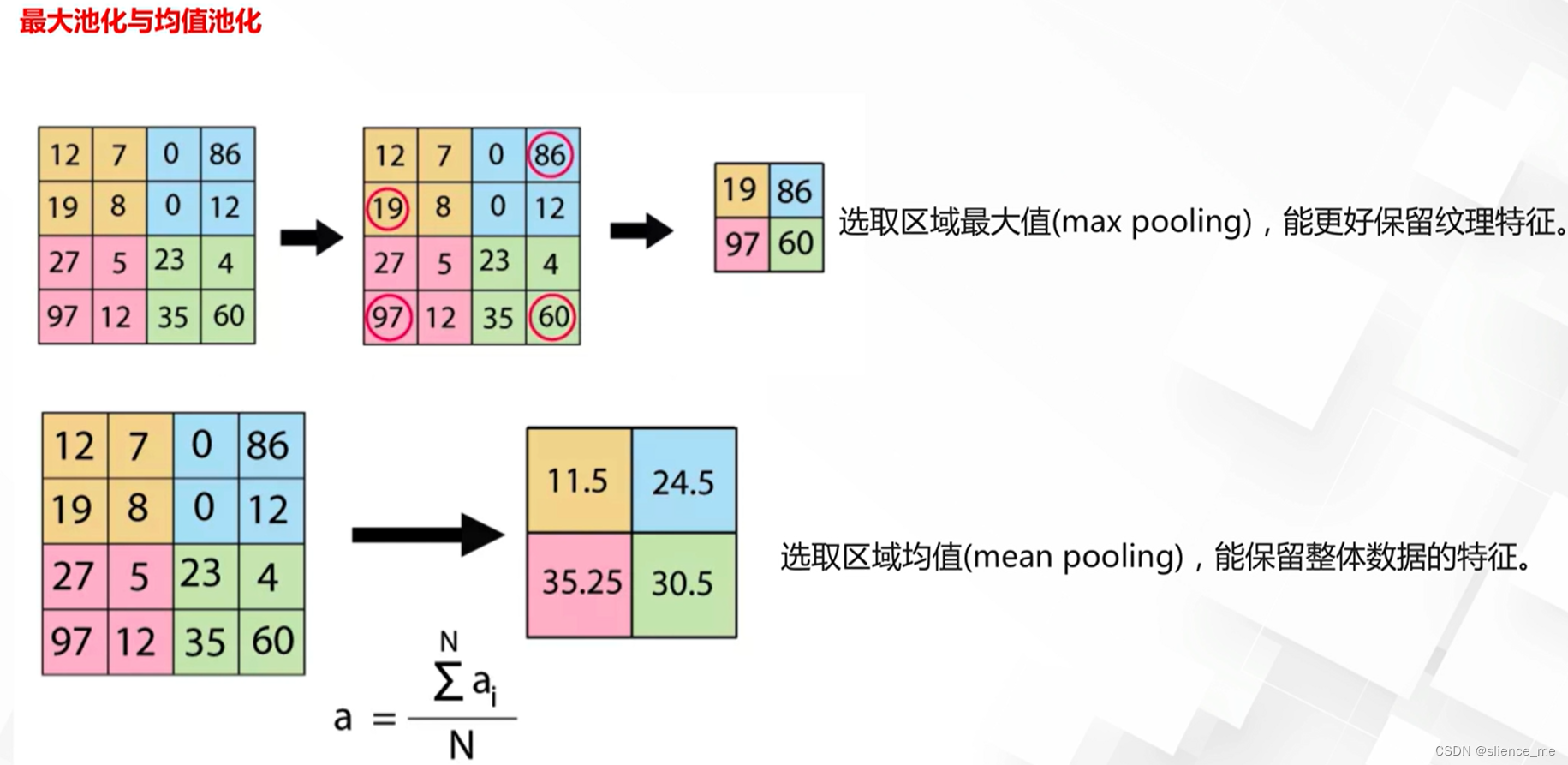
- 最大值池化(Max Pooling):
- 操作方式:在每个池化窗口内选择最大值作为输出。
- 特点:Max Pooling突出最显著的特征,通常用于提取重要的特征。
- 均值池化(Average Pooling):
- 操作方式:在每个池化窗口内计算所有值的平均值作为输出。
- 特点:Average Pooling平滑特征图并减小尺寸,用于降低计算量。
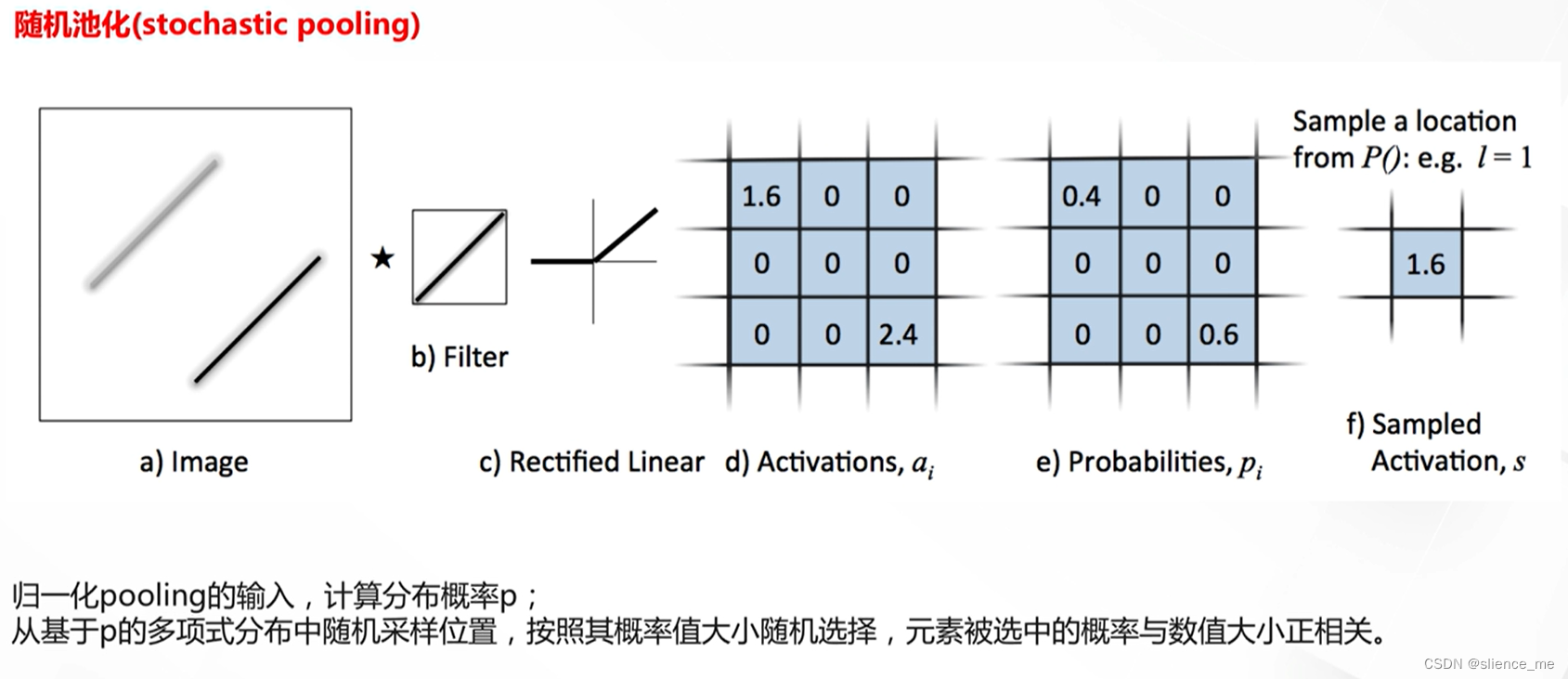
- 随机池化(Random Pooling):
- 操作方式:在每个池化窗口内随机选择一个值作为输出。
- 特点:Random Pooling引入了随机性,有助于提高网络的鲁棒性和泛化性能。
- 最小值池化(Min Pooling):
- 操作方式:在每个池化窗口内选择最小值作为输出。
- 特点:Min Pooling可用于强调较小的特征值,用于特定任务。
- 中值池化(Median Pooling):
- 操作方式:在每个池化窗口内选择中值(中间值)作为输出。
- 特点:Median Pooling可以在一定程度上抵御异常值的影响,适用于一些异常值敏感的任务。
- 混合池化(Mixed Pooling):
- 操作方式:结合多种池化策略,可能以一定的权重混合它们的输出。
- 特点:Mixed Pooling允许根据任务的需要结合不同的池化策略,提高网络的灵活性。
这些池化方法之间的选择通常取决于具体的任务和数据,以及希望突出的特征。混合池化则允许根据需求结合多种池化策略,以实现更大的灵活性。在实际应用中,通常需要进行实验和调整以确定哪种池化方法最适合特定任务。
2.4 池化的必要性
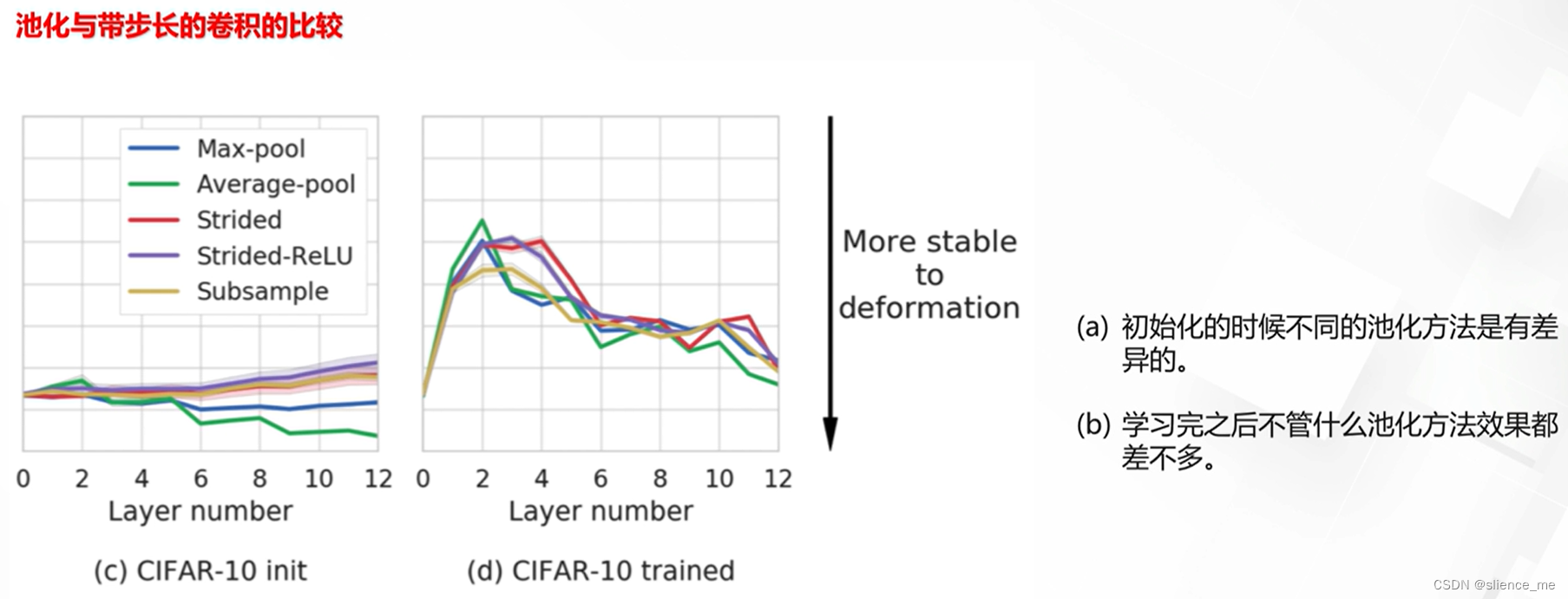
注意:现阶段常常采用带步长的卷积代替池化操作
部分内容来自: 阿里云天池
文档信息
- 本文作者:slience_me
- 本文链接:https://slienceme.xyz/2023/10/24/%E6%A0%87%E5%87%86%E5%8C%96%E4%B8%8E%E6%B1%A0%E5%8C%96%E5%90%88%E9%9B%86/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)